.svg)
Entregue los pedidos de su mercado a tiempo con el aprendizaje automático
Nuestras recomendaciones para crear un predictor del tiempo de preparación


Este post es una entrada a nuestro Marketplaces de tres caras y serie de aprendizaje automático. En nuestra introducción mencionamos una de las posibles formas de mejorar un Marketplace: predecir el tiempo de preparación de un pedido. Disponer de esta información aporta dos grandes ventajas a cualquier Marketplace: ahora los usuarios tienen una estimación de cuándo llegará su pedido a casa y, además, se puede mejorar la logística, ya que ahora se pueden asignar de forma inteligente los servicios de mensajería en función del momento en que el pedido estará listo.
Esta publicación se puede leer como una entrada independiente, pero no dudes en consultar la introducción, te dirá qué son los Marketplaces y cómo Aprendizaje automático ¡puede optimizarlos!
Otro concepto clave aquí es que trabajaremos con Datos de series temporales, una serie de puntos de datos ordenados en el tiempo. Una vez que tengamos esto dato, es posible pronóstico y predice sus valores futuros basándose en los valores observados anteriormente. Hay mucho de qué hablar sobre este tema (y es posible que hagamos un post de seguimiento sobre Previsión de series temporales ¡más tarde!) pero para esta entrada solo sabiendo que Datos de series temporales implicar una serie de puntos de datos en el tiempo es suficiente.
Esta publicación detalla algunas de las experiencias que obtuvimos al resolver un predicción del tiempo de preparación problema en el negocio de entrega de comida. Aprendimos mucho sobre su funcionamiento interno y sobre cómo adaptar sus necesidades a un Aprendizaje automático problema, ¡y nos gustaría compartirlo contigo!
El problema
En primer lugar, expongamos el problema con claridad en el contexto de un mercado de alimentos: una vez que pedido está confirmado y aceptado por un restaurante, ¿cuánto falta para que esté listo y podamos ir a recogerlo? Esto significa que nos centraremos en predecir la tiempo de preparación de un pedido, no al predecir toda su duración.
Esto se puede obtener añadiendo nuestro tiempo de preparación predicción a un tiempo de viaje predicción (por ejemplo, desde cualquier servicio de GPS), ya que el mensajero solo tiene que viajar del punto A al punto B.
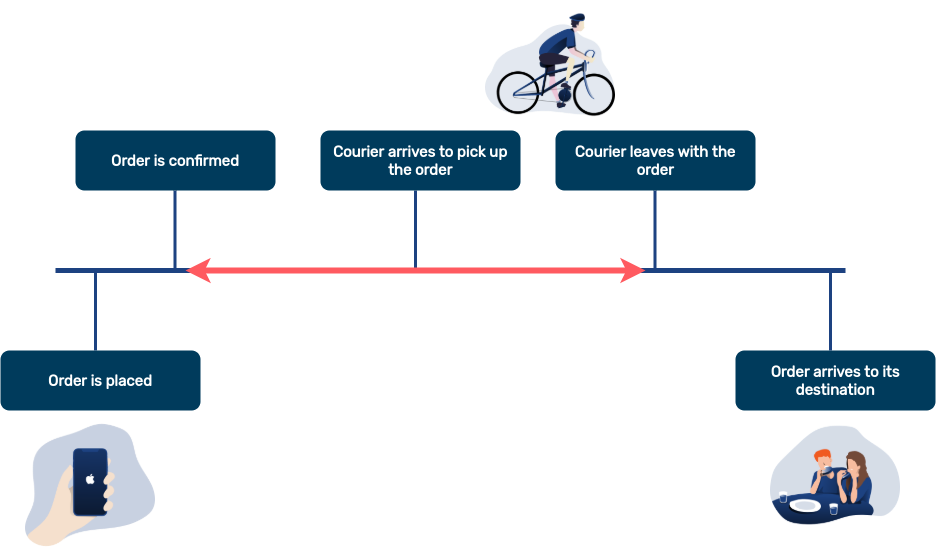
Teniendo en cuenta todo el cronograma de un pedido, estamos intentando predecir una cantidad de tiempo variable que se produce durante la línea roja: comienza cuando se confirma el pedido y termina cuando el servicio de mensajería recoge el artículo. Sin embargo, un mensajero puede esperar más tiempo si llega antes de que el pedido esté realmente listo, o puede que el pedido pase mucho tiempo en el mostrador del restaurante si lo recogemos tarde.
Como hemos mencionado, conocer el tiempo de preparación de un pedido sería fantástico para la logística: ¡con él sabríamos la hora aproximada en la que los mensajeros deberían estar cerca de los restaurantes para recoger un pedido! Desde el punto de vista empresarial, esto se traduce en una menor pérdida de tiempo esperando los pedidos que no están listos y en garantizar que nuestros transportistas puedan entregarlos a tiempo.
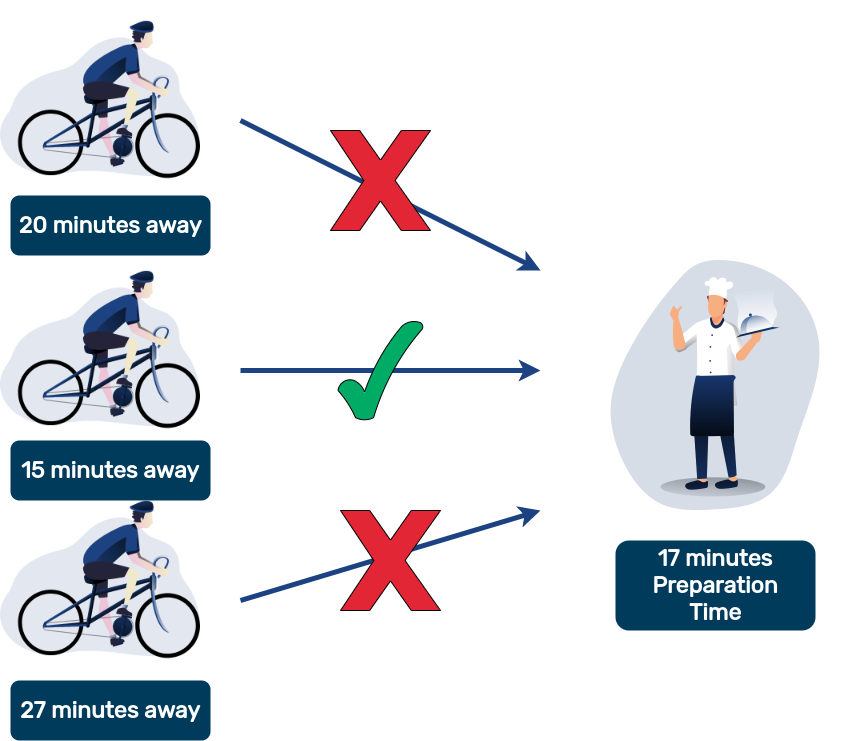
En Aprendizaje automático términos esto significa que el columna y queremos predecir el tiempo de preparación (en cualquier unidad de tiempo, como segundos o minutos) de un pedido, y queremos que sea lo más parecido posible al real.
Hay dos aspectos del mercado que pueden ayudarnos a obtener datos para resolver este problema:
- Restaurantes notifique que la comida está lista para ser recogida.
- Mensajería vayan al restaurante y puedan avisarnos si tuvieron que esperar porque la comida no estaba realmente lista.
Pero, ¿por qué tratar de predecir esto? ¿En cualquier entrega de comida normal Marketplace los restaurantes notifican a la aplicación cuando la comida está lista y esa notificación siempre debe ser precisa, ¿verdad? ¿Qué necesidad hay de predecir el tiempo de preparación? Si recibimos un pedido de hamburguesa el martes, debería tardar exactamente el mismo tiempo que el lunes. Lamentablemente, este no es el caso. Estas son algunas de las razones por las que usar un Aprendizaje automático la solución es mucho mejor:
- Adaptable a escenarios del mundo real: la verdad es que el mismo artículo no siempre llevará el mismo tiempo de preparación. Por ejemplo, si el restaurante tiene demasiados pedidos al mismo tiempo, incluso un pedido simple puede tardar más de lo esperado.
- Los restaurantes notifican que la comida está lista demasiado tarde o demasiado pronto: los restaurantes no son perfectos. Si forman parte de nuestro Marketplace, luego deberán notificar ellos mismos que el pedido está listo. Incluso si nuestra aplicación de integración es excelente y tiene una interfaz de usuario muy clara, esto requiere tiempo. Y resulta que algunos se olvidan de notificar que el pedido está listo para ser recogido, dejando que se enfríe. ¡Y descubrimos que algunos incluso intentan jugar con el sistema notificando que el pedido está listo de inmediato!
Queremos que nuestra predicción sea válida incluso cuando los restaurantes no notifiquen que el pedido está hecho y que se adapte a las diferentes condiciones de vida (cantidad actual de pedidos, festividades, clima, etc.). Estos dos requisitos se pueden cumplir con la ayuda de algunos ingeniería de funciones, limpieza de datos y agregar la lógica empresarial a nuestro sistema de aprendizaje automático. Estas herramientas ayudarán a todos los restaurantes de nuestro Marketplace, pero como cada restaurante es su propio mundo, un mundo único Aprendizaje automático el modelo tiene que ser entrenado para cada uno de ellos. Vamos a profundizar en estas ideas.
Ingeniería de funciones
Las buenas características son clave para el rendimiento de cualquier Aprendizaje automático sistema. En este caso, nos permitirán modelar lo que ocurre en el mundo real cuando se hace el pedido en un restaurante. ¿El restaurante recibe muchos pedidos? ¿Cuánto tiempo han tardado en preparar ese plato en las últimas horas? ¿Y qué hay de la semana pasada? Toda esta información se puede traducir al características y solía tren la Aprendizaje automático algoritmo. Éstos son algunos de los que hemos tenido más éxito:
- Tiempo de preparación pasado: funciones retrasadas son un clásico básico de Datos de series temporales. Transforman la información de eventos pasados en una función. Saber cuánto tiempo tardó el mismo pedido en el pasado es un buen indicador de cuánto tiempo debería tardar ahora mismo. Por supuesto, la información retrasada que utilizamos como función debería estar relacionada de alguna manera con el pedido: saber cuánto tiempo tardó el mismo día, a la misma hora de la semana pasada y cuánto tiempo ha estado tardando las últimas horas es una buena idea.
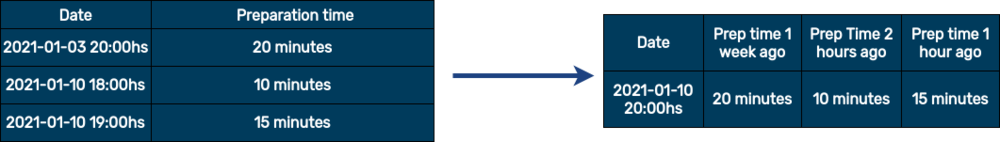
No solo eso, sino usar promedios tampoco es una mala idea, por ejemplo, si nadie ha pedido ese artículo en las últimas horas o la semana pasada, entonces un media podría ser la segunda mejor opción si consigue una media de tiempo de preparación durante todo el día.
- Cantidad de pedidos en las últimas horas: si un restaurante está muy concurrido, es probable que tarden más en cocinar su comida. Sumar la cantidad de pedidos que han recibido en las últimas horas podría ser un buen indicador de lo ocupados que están en este momento.
- Precio e importe del pedido: como propietario del Marketplace lo más probable es que cuando realices un pedido sepas que es precio y cuántos había objetos en él. Estas pueden ser excelentes características, tal vez el restaurante dedique más tiempo a cada artículo del pedido o priorice los artículos caros cocinándolos primero. Esto rasgo ayudará a encontrar cualquiera de estas correlaciones.
- Clima actual y futuro: el clima es una causa habitual de retrasos no solo en la entrega, sino también en la preparación de un pedido. La gente tiende a quedarse en casa los días en los que hace mal tiempo, ¡y más gente se queda en casa significa que llegan más pedidos! Esta demanda mayor de lo habitual suele traducirse en tiempos de preparación más largos.
- Categorización de las horas punta: el hecho de que la comida se haya preparado durante el desayuno, el almuerzo o la cena puede marcar la diferencia. Esto rasgo es bastante simple, ya que es fácil obtener la hora en la que se realizó el pedido y usarla para definir si se hizo durante una hora punta o no.
- Función de vacaciones: de manera similar a la categorización de las horas punta, es posible saber si un pedido se realizó en un día festivo. En lugar de programar de forma rígida todas las fechas festivas posibles, te recomendamos que utilices una biblioteca como vacaciones.
Limpiar los datos del restaurante
Una parte clave del Aprendizaje automático el proceso está limpiando los datos disponibles. Tener más datos es fantástico, pero introducir datos incorrectos o sucios en nuestro sistema solo disminuirá su rendimiento. Los restaurantes pueden proporcionarnos información incorrecta de forma accidental o deliberada. ¿Cómo podemos detectar si ese es el caso? ¿Es posible guardar esos datos?
Un buen primer paso para abordar un problema nuevo es hacer algo bueno exploración de datos, y visualizaciones son clave aquí. Nos ayudarán a entender a qué nos enfrentamos y a compartir esos hallazgos para luego tomar decisiones informadas. Sin embargo, al principio, tus visualizaciones pueden acabar teniendo el siguiente aspecto:
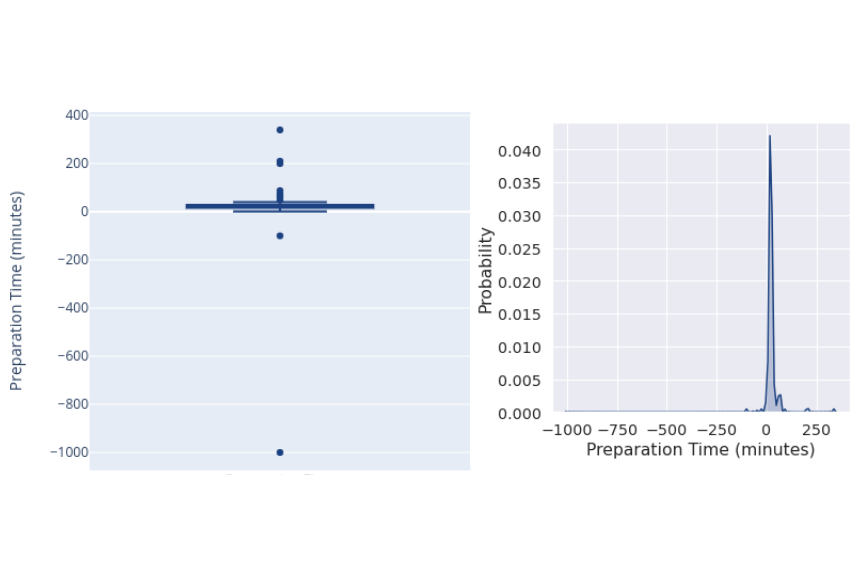
¡Pero no todo está perdido! Esto nos dice que tenemos algo serio valores atípicos en nuestros datos, tanto positivos como negativos. Esto requiere algunos Limpieza de datos. Dos cosas que descubrimos que funcionan bien son:
- Descartar valores atípicos extremos, como valores negativos o increíblemente altos. Por alguna razón, debido a un problema con la interfaz de usuario o a que un restaurante se haya olvidado de informar de que el pedido estaba listo, el valor no tiene sentido. Descartarlo es la mejor opción en este caso.
- Establece un umbral y clip valores superiores o inferiores a esos umbrales. No es del todo improbable que un pedido tarde muy poco o mucho tiempo (por ejemplo, un pedido que tarda 3 minutos o 90 minutos) sin que se produzca un error. Siguen siendo valores atípicos, pero los datos son correctos. Parte de la adaptación de nuestra lógica empresarial a una buena Aprendizaje automático systems está adaptando estos valores a las necesidades de nuestra empresa: algunos pedidos pueden tardar 3 minutos en prepararse, pero es posible que preferimos que nuestras predicciones se equivoquen por exagerar en este caso. Esto evita que las empresas de mensajería lleguen demasiado pronto si la predicción es errónea. La misma idea se aplica a los pedidos que tardan demasiado: es posible que preferimos subestimar esos casos para no llegar demasiado tarde. Recortar ayuda con esto, por ejemplo, si definimos el intervalo
[i, j]todos los valores inferiores aison reemplazados por él, y todos los valores superiores ajconvertirj.
Hagamos lo que acabamos de decir y descarte esos valores atípicos extremos y usa un clip de [5, 45].
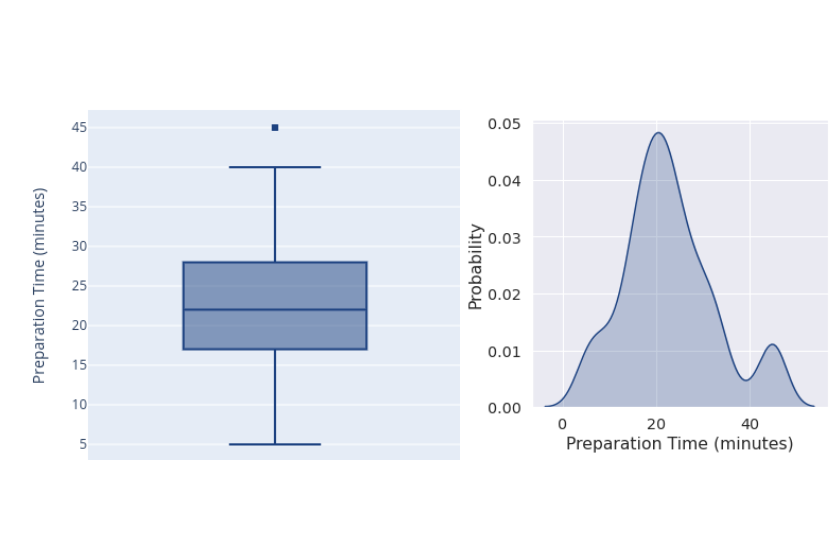
¡Mucho mejor! Ahora sabemos que los datos que utilizaremos para entrenar nuestro algoritmo nunca superarán los 45 minutos ni estarán por debajo de los 5 minutos. Parece que la mayoría de nuestros pedidos rondan el intervalo de 15 a 25 minutos.
Métricas y adaptación de la lógica empresarial
Ya hemos mencionado cómo recorte valores que estábamos adaptando lógica empresarial en nuestro Aprendizaje automático sistema. La elaboración de métricas que vinculen el sistema con nuestros objetivos empresariales también forma parte de este proceso, ya que nos ayuda a entender si el sistema ayuda al negocio y de qué manera. Por experiencia, sabemos que este paso es tan o incluso más fructífero que un paso complejo Aprendizaje automático técnicas.
Hay muchas funciones clásicas que pueden medir el error de un Aprendizaje automático sistema. Error absoluto medio, Error cuadrático medio o Error de raíz cuadrada funcionan muy bien para medir los errores al entrenar nuestro algoritmo de regresión supervisada, pero es difícil entender cómo estos resultados afectan realmente a nuestro negocio. Una alternativa fácil y sencilla es MAPE (Error porcentual promedio). Traduce estas métricas de un número de error a un porcentaje de error. A MAPE del 30% significa que, en promedio, nuestras predicciones tienen un 30% de descuento. Entonces podemos decidir si este porcentaje es bueno o no para nuestro negocio.
MAPE es una métrica clásica que se adapta a todos los problemas, pero se toma el tiempo necesario para crear una métrica personalizada que se adapte a nuestras necesidades empresariales específicas también es una gran idea. ¿Preferimos que nuestros transportistas lleguen a su destino antes de que el pedido esté listo? ¿O quizás más tarde? ¿Queremos saber si nuestro modelo es más preciso en pedidos caros? Estas cosas y más se pueden medir con un métrica personalizada, pero nos toca a nosotros construirlo. Y son útiles para más cosas que simplemente medir el desempeño de la empresa: podemos capacitar a nuestros Aprendizaje automático sistema para optimizar sus resultados en función de cualquiera de estas métricas.
Por ejemplo, supongamos que tienes un objetivo empresarial no llegar nunca 20 minutos tarde para recoger un pedido. Si nuestras predicciones provocan eso, significa que nuestro sistema es prediciendo en exceso, lo que hace que el mensajero llegue 20 minutos tarde a su destino. Para paliar esto, podemos castigar esos errores ponderándolos de manera diferente en nuestra función y usar esa función para entrenar nuestro algoritmo. Esto no garantiza el mejor rendimiento general de nuestro sistema, pero ayudará a que se adapte a su objetivos empresariales mucho más.
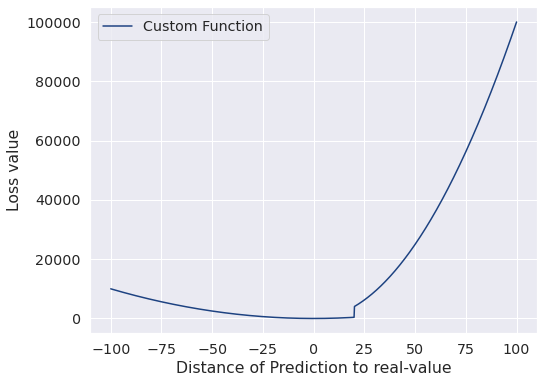
Este artículo por Príncipe Grover y Sourav Dey tiene mucha más información sobre cómo entender esta idea e implementarla.
Y buenas noticias: todos Aprendizaje automático bibliotecas que tienen un Scikit-Learn la interfaz puede hacer esto fácilmente. Por ejemplo, este es el Interfaz Scikit-Learn Wrapper para XGBoost. Según la implementación del artículo, así es como se ve el código:
defcustom_asymmetric_objective (y_true, y_pred) :"""Calcule una función objetivo asimétrica que castigue las grandes sobrepredicciones. Implementación basada en: https://towardsdatascience.com/custom-loss-functions-for-gradient-boosting-f79c1b40466d"""residual=(y_true-y_pred).astype("float")grad=np.where((residual<-20),-2*10.0*residual,-2*residual)hess=np.where((residual<-20),2*10.0,2.0)returngrad,hess
Utilizar esta función como objetivo el parámetro hará el truco.
Seguimiento de nuestro crecimiento con MLFlow
Durante este artículo mencionamos muchas formas posibles de mejorar el rendimiento de un tiempo de preparación sistema de predicción. Características, métricas, diferentes formas de entrenar nuestro algoritmo e incluso limpiar los datos. Pero, ¿cómo sabemos que nuestros nuevos cambios dan buenos resultados a lo largo del tiempo? Por supuesto, las métricas son una excelente forma de comprobar esto, pero analizándolas una vez antes de la implementación no es suficiente para determinar si nuestros cambios fueron mejores o peores. La gente suele olvidar eso Aprendizaje automático los sistemas siguen software, y una buena ingeniería de software significa que el rendimiento del software debe supervisarse constantemente. Tenemos que pista nuestro sistema a lo largo de su ciclo de vida mediante múltiples métricas. Aquí es donde MLFlow viene a ayudar.
MLFlow encaja en el Aprendizaje automático ciclo de vida por rastreo sus resultados, embalaje el modelo debe ser fácilmente reproducible, desplegando se adapta a cualquier sistema y tiene un registro de modelos anteriores. Todas estas son excelentes características, pero en esta entrada nos centraremos en sus rastreo componente. En nuestros proyectos, nos ayuda a controlar si cada una de las características y cambios que mencionamos arrojó resultados positivos o no. Si desea obtener más información sobre cómo funciona MLFlow y lo que puede hacer, tiene un impresionante documentación para cada uno de sus componentes.
Lo importante que debes saber MLFlow es que tiene un servidor de seguimiento que apoya el ahorro métricas, parámetros y artefactos (cualquier tipo de archivo, por ejemplo un .csv o una imagen gráfica) y una interfaz de usuario para interactuar con estos datos. Tener una interfaz de usuario es genial porque no solo quien programó el sistema puede comprobar y analizar los resultados: ahora todos los miembros del equipo pueden hacerlo, incluso si no son tan expertos en tecnología.
Estas son algunas recomendaciones basadas en nuestra experiencia:
- Un buen nombre para el experimento le ayudará a encontrar fácilmente los resultados que busca. En nuestro caso, ya que cada restaurante obtuvo su propio modelo y el experimento se llevó a cabo cada hora, utilizamos el siguiente formato:
<EXPERIMENT_NAME>_ <YYYY-MM-DD hh:ss> - No te olvides de usar los parámetros para rastrear qué funciones y configuraciones se usaron durante el entrenamiento del modelo. Siempre es una buena idea poder activar, desactivar y modificar las funciones mediante la configuración. ¡Haz un seguimiento de esa información como parámetros y comprueba qué configuración obtiene los mejores resultados!
- Guardar archivos como artefactos nos permite visualizar gráficos, datos sin procesar e incluso de forma interactiva
.htmlarchivos! Cuando las cosas van mal, una buena trama te permitirá visualizar cuando y cómo tus resultados empezaron a empeorar. En este problema, descubrimos que al usar un mapa de calor mostrar el rendimiento de cada una de nuestras métricas durante el día fue de gran ayuda. Y para comprobar que hemos limpiado y procesado correctamente nuestros datos, almacenamos una muestra de los datos para asegurarnos de que tienen el aspecto correcto. - Consulta los resultados de tu experimento localmente con MLFlow, usar la interfaz de usuario de MLFlow puede resultar un poco engorroso una vez que queremos hacer un análisis más refinado de los resultados. Es fácil echarle un vistazo rápidamente, pero lo ideal es poder hacer un análisis profundo analizando todos los puntos de datos disponibles para determinar si nuestros últimos cambios arrojaron resultados positivos o no. Este es el motivo MLFlow permite consultas programáticas eso se puede hacer en cualquier lugar, incluso localmente, siempre que tenga acceso al servidor. Usando su sintaxis de búsqueda ¡puedes obtener todos los parámetros y las métricas resultantes de tus experimentos!
Hay aún más de qué hablar MLFlow, ¡pero dejaremos los ejemplos de código y la discusión profunda para la próxima entrada!
Algunas posibles mejoras
Lamentablemente, no pudimos hacer todas las cosas que queríamos hacer. Nos faltó tiempo para algunas de ellas, ¡y otras las descubrimos demasiado tarde! Estas son algunas de las posibles mejoras que podrían impulsar cualquier predicción del tiempo de preparación solución:
- Más funciones: hemos enumerado solo algunas de las funciones con las que hemos obtenido buenos resultados, ¡pero hay muchas cosas que probar! Por ejemplo, si tuvieras dato al indicarle la cantidad de personal que trabaja actualmente en la cocina, podría ser un buen indicador de cuánto tiempo tiempo de preparación tendrá y sería una gran característica.
- Sobremuestreo de datos: restaurantes con bajo volumen de los pedidos son comodines. Como no obtenemos muchos datos para entrenar nuestro algoritmo, es posible que el modelo tenga predicciones muy inconsistentes. Valdría la pena probarlo sobremuestreo cuando sus conjuntos de datos están realmente desequilibrados.
- Probando diferentes modelos: cada restaurante es su propio mundo, y nuestro modelo tiene que adaptarse lo mejor posible a su realidad para obtener los mejores resultados. Nosotros entrenó cada modelo con los datos de cada restaurante, pero tal vez restaurantes con un bajo volumen de los pedidos necesitan un modelo completamente diferente al de los que tienen un alto volumen de pedidos. Descartar y añadir funciones y probar diferentes bibliotecas y técnicas son solo algunas de las cosas que podemos hacer para adaptar nuestros modelos a la medida y obtener los mejores resultados.
Ejecutando esto en producción
Lograr que esto funcione de manera confiable en producción es una tarea completamente diferente. Queremos que nuestro sistema actualice sus predicciones con bastante frecuencia y dado que la mayoría de las funciones las utilizan datos recientes entonces tiene sentido actualizarlo cada hora. ¡Pero eso significa que toda la extracción de datos, la ingeniería de funciones, el entrenamiento de modelos, la validación de datos, el seguimiento y el almacenamiento de los resultados deben realizarse cada hora! Por supuesto, no podemos ejecutarlo manualmente cada hora, lo que significa que queremos un automatizado proceso que hace todo esto de manera confiable. Uso de herramientas como cron puede ser una buena primera solución, pero carece de la capacidad de volver a ejecutar todo el proceso o solo uno de sus pasos, informes que nos notifiquen si algo salió mal y una buena interfaz de usuario para que la use cualquiera.
Para resolver esto, nuestra solución preferida es Flujo de aire Apache, que nos permite programar y supervisar cualquiera de nuestros flujos de trabajo. Haciendo nuestro predicciones de tiempo de preparación cada hora está a solo una configuración de distancia, y cualquiera puede volver a ejecutar cualquier proceso fallido simplemente usando su interfaz de usuario. Planeamos hablar más sobre *gestión del flujo de trabajo en el futuro, ¡y te contaremos nuestros casos de uso y todos los consejos y trucos que hemos aprendido a lo largo del camino!
Referencias
Sí, Sourav. Grover, Príncipe. «Funciones de pérdida personalizadas para aumentar el gradiente». Hacia la ciencia de datos, URL
La fuente de la imagen del encabezado es Wikimedia Commons:
La vida de Benjamin Franklin: Holley, O. L. (Orville Luther), 1791-1861 Anderson, Alexander, 1775-1870 DLC de la Colección Benjamin Franklin (Biblioteca del Congreso). URL
_(14764132512).jpg){kind=link}
Latest Insights

Building a Modern Data and AI Platform on Databricks: Architecture, Migration, and Implementation

Muttdata closes its first investment round to accelerate growth across the Americas

Building a Marketing Data Platform on Databricks: Architecture, Use Cases, and Real Results
