.svg)
Seguimiento del rendimiento de sus modelos de aprendizaje automático con MLflow
Empiece a trabajar y comience a rastrear su sistema de aprendizaje automático

En nuestro Entregue los pedidos de su mercado a tiempo con el aprendizaje automático entrada hablamos de lo importante que es hacer un seguimiento de los resultados de Aprendizaje automático experimentos y oleoductos. Hay muchas partes que se modifican constantemente y que hay que tener en cuenta: diferentes modelos, características, parámetros, fuentes de datos cambiantes, hiperparámetros y, en conjunto, nuevas formas de entrenar el algoritmo. La única forma de conocer el efecto de esos cambios es monitorizarlos.
Es por eso que utilizamos MLFlow a DATOS DE CHUCOS. Descubrimos que es una excelente herramienta para rastrear los resultados de nuestros experimentos en entornos de producción y nos ayudó a mejorar la forma en que comunicar los resultados de nuestro Aprendizaje automático sistemas para nuestros clientes. Este es el por qué Operaciones de aprendizaje automático (MLOP) es más importante que nunca: ya no basta con tener buenos resultados en nuestras predicciones o previsiones, necesitamos hacer todo el sistema de confianza, monitorizable, automática y escalable
Esta publicación sirve tanto como una entrada independiente como como una adición técnica a la Entregue los pedidos de su mercado a tiempo con el aprendizaje automático publicar. No encontrarás los conceptos básicos y fundamentales de MLFlow aquí, sino algunos consejos y trucos que hemos aprendido a lo largo del camino para ayudarlo a comenzar de la manera más rápida y eficiente posible.
Todo el código y los ejemplos utilizados para esta publicación están en este repositorio: Muttdata/MLFlow_Article_Code. ¡Siéntete libre de ejecutar, modificar y jugar con los fragmentos de código como quieras!
Qué aprenderás en este post
Durante esta entrada mostraremos cómo configurar fácilmente MLFlowes el servidor, la interfaz de usuario y la base de datos usando docker-compose. Luego implementaremos los consejos mencionados en Entregue los pedidos de su mercado a tiempo con el aprendizaje automático:
- Definir un buen experimento y nombre de ejecución
- Uso de parámetros para realizar un seguimiento de las funciones y las configuraciones importantes
- Guardar archivos útiles como artefactos
- Consulta los resultados de tus experimentos a nivel local
Hay mucho más que hacer y mostrar MLFlow, pero esperamos que estos trucos y ejemplos de código te ayuden a empezar a rastrear tus Aprendizaje automático ¡experimenta lo más rápido posible!
Seguimiento del ciclo de vida del aprendizaje automático
El aprendizaje automático sigue siendo una pieza de software, y es clave estar al tanto de su rendimiento. Necesitamos saber si nuestros últimos cambios afectaron el rendimiento de manera positiva o no, y comprobar sus resultados una vez durante el desarrollo no es suficiente. después despliegue el sistema comienza a funcionar con datos reales y pueden suceder varias cosas. En el mejor de los casos, los resultados son consistentemente mejores, ¡pero también puede ocurrir que su rendimiento al principio sea bueno pero comience a degradarse con el tiempo! La única forma de estar al tanto de esto es constantemente pista y monitor sus resultados.
Usamos MLFlow para ello: proporciona un servidor de seguimiento donde es posible almacenar parámetros, métricas y artefactos (archivos como .png parcelas o .csv archivos) y una buena interfaz de usuario donde cualquiera puede comprobar sus resultados. Si quieres saber más al respecto, echa un vistazo a su increíble documentación y inicio rápido.
Después de trabajar con él durante un tiempo, tenemos algunos consejos y trucos para compartir que, con suerte, harán que empezar a hacer un seguimiento de los resultados sea una mejor experiencia.
Usaremos un Serie temporal de ventas minoristas, una de las muestras del Profeta repositorio.
Nuestro código solo sirve como un ejemplo de cómo se puede hacer uso de MLFlow para rastrear un Aprendizaje automático solución, por lo que utiliza modelos y funciones extremadamente ingenuos.
Configurar las cosas
MLFlow tiene dos componentes clave: el servidor de seguimiento y el UI. Para empezar a interactuar con ellos, tendremos que poner en marcha estos servicios.
La instalación y el mantenimiento manuales de dos servicios como estos pueden ser un poco complicados a veces. Y no solo eso, sino que si quieres almacenar de forma segura los resultados de tus experimentos, tendrás que iniciar un base de datos. Aquí es donde docker-compose viene a salvar el día, ya que hace que configurar todos esos servicios juntos y cambiar sus configuraciones sea pan comido. Esto es simple docker-compose«receta» para arrancar rápidamente MLFlow y sus servicios requeridos. Esto docker-compose necesitaría algunos ajustes para un entorno de producción (por ejemplo, girando nginx para la autenticación), pero es una excelente manera de acceder a él y empezar a usarlo:
versión: '3' servicios: postgresql: image:postgres:10.5 entorno: POSTGRES_USER: $ {POSTGRES_USER} POSTGRES_PASSWORD: $ {POSTGRES_PASSWORD} postGRES_DB:MLFLOW-DB POSTGRES_INITDB_ARGS:» --encoding=UTF-8"restart:Always volumes: -mlflow-db: /var/lib/postgresql/data ports: -0.0.0. 0:5432:5432 waitfordb: image:dadarek/wait-for-dependencies depends_on: -postgresql command:postgresql:5432 mlflow-server: build:. ports: -0.0.0. 0:5000:5000 entorno: db_URI:postgreSQL+Psycopg2: //$ {POSTGRES_USER} :$ {POSTGRES_PASSWORD} @postgresql :5432/mlflow-db MLFLOW_ARTIFACT_ROOT: "$ {MLFLOW_ ARTIFACT_ROOT} "MLFLOW_TRACKING_USERNAME:" $ {MLFLOW_TRACKING_USERNAME} "MLFLOW_TRACKING_PASSWORD:" $ {MLFLOW_TRACKING_PASSWORD} "restart:always depends_on: -waitfordb volumes: -"$ {MLFLOW_ARTIFACT_ROOT}" mlflow-ui: build:. ports: -0.0.0. 0:80:80 entorno: db_URI:PostgreSQL+PsycoPG2: //$ {POSTGRES_USER} :$ {POSTGRES_PASSWORD} @postgresql:5432/mlflow-db MLFLOW_TRACKING_USERNAME: "$ {MLFLOW_TRACKING_USERNAME}" MLFLOW_TRACKING_PASSWORD: "$ {MLFLOW_TRACKING_PASSWORD}» MLFLOW_TRACKING_PASSWORD: "$ {MLFLOW_TRACKING_PASSWORD}» MLFLOW_TRACKING_PASSWORD: "$ {MLFLOW_TRACKING_PASSWORD}» MLFLOW_TRACKING_PASSWORD: _ARTIFACT_ROOT: "$ {MLFLOW_ARTIFACT_ROOT}" reiniciar:always depends_on: -mlflow-server punto de entrada:. volúmenes de /start_ui.sh: -"$ {MLFLOW_ARTIFACT_ROOT} :$ {MLFLOW_ARTIFACT_ROOT}» volúmenes: -mlflow-db: driver:local
Corre docker-compose up ¡y estarás listo para partir! En pocas palabras, esto docker-compose arrancará un PostgreSQL base de datos para almacenar resultados, de MLflow servidor en el puerto 5000 y es UI en el puerto 80. Algunas configuraciones se pueden cambiar modificando el .env archivo. MLFlow almacenará sus archivos en /tmp/ml se ejecuta de forma predeterminada, pero puede cambiarlo modificando el .env expediente en el repositorio.
Esto debería ser suficiente para una configuración inicial, pero si quieres asegurarte de que todos estos servicios permanecen activos después de implementarlos, utiliza una herramienta como supervisores es una gran idea. Es un Sistema de control de procesos, donde puede configurar fácilmente el reinicio de los procesos en caso de que se caigan.
Empezar a realizar un seguimiento de las métricas y los parámetros
Empecemos por entrenar a un XG Boost modelar y luego rastrear algunas métricas y parámetros. Es bastante fácil empezar a rastrear algunas métricas usando De MLFlow API:
withmlflow.start_run (): [...] # Calcula las métricas de MSE se=mean_squared_error (y, y_hat) mlflow.log_param («MSE», mse)
Puedes correr este archivo en el repositorio para hacer precisamente eso.
Después de esto, la interfaz de usuario tendrá una entrada para el experimento:
Pero esto no es lo ideal: no tenemos forma de diferenciar entre los experimentos además de su Hora de inicio, el seguimiento de una sola métrica no parece muy útil y no sabemos nada sobre las funciones, los hiperparámetros o las configuraciones utilizadas.
Para diferenciar entre tus carreras, asegúrate de tener un buen experimento y un nombre de ejecución buenos y con capacidad de búsqueda. Piensa en nombres de experimentos como una forma de agrupar todo tu proyecto, y nombre de ejecución como una forma de diferenciar el tipo de carrera que estabas haciendo. Por ejemplo, Previsión de venta minorista podría ser un buen nombre para el experimento y predicción_de_tienda_ <RUN_DATE> podría funcionar como nombre de ejecución.
Pero eso no es todo, es importante rastrea las funciones que usaste. De esta forma, sabrá qué causó sus resultados. Una forma sencilla de hacerlo es hacer un seguimiento del nombre de las columnas de funciones que utilizaste durante el entrenamiento.
current_date=date.today () experiment_id=mlflow.set_experiment («Previsión minorista») [...] withmlflow.start_run (run_name=f"retail_prediction_ {current_date}»): [...] # Calcular las métricas de MSE = mean_squared_error (y, y_hat) mlflow.log_param («MSE», mse) # Track featuresmlflow.log_param («Features», x.columns.ToList ()) mlflow.log_param («Date», current_date)
Ahora sabemos exactamente qué funciones utilizamos durante el entrenamiento.
Se puede ver el código con estos cambios aquí.

Guardar gráficos y archivos
Vamos a tener que rastrear algo más que métricas y parámetros si queremos entender nuestros resultados. Ya que estamos pronosticando un Serie temporal, un gráfico de líneas ayudará a entender cómo se ven nuestras predicciones. Al igual que en los ejemplos anteriores, podemos hacerlo con De MLFlow API:
withmlflow.start_run (run_name=f"retail_prediction_ {current_date}»): [...] # Guarda el gráfico en MLFlowfig, ax=create_line_plot (x_test, y_test, yhat_test) fig.savefig (f "{MLFLOW_ARTIFACT_ROOT} /line_plot.png») mlflow.log_artifact (f "{MLFLOW_ARTIFACT_ROOT}») mlflow.log_artifact (f "{MLFLOW_ARTIFACT_ROOT}») ARTIFACT_ROOT} /line_plot.png») plt.close () [...]
Pero a veces tener un poco de datos sin procesar también es una buena idea, solo para saber con qué estábamos trabajando cuando entrenamos nuestro algoritmo. MLFlow soporta .csv e incluso extensiones interactivas como .html!
# Guarde una muestra de datos sin procesar como ArtifactSample_Data=x_test.sample (min (MIN_SAMPLE_OUTPUT, len (x_Test))) sample_data.to_csv (f "{MLFLOW_ARTIFACT_ROOT} /sample_data.csv») mlflow.log_artifact (f "{MLFLOW_ARTIFACT_ROOT} /sample_data.csv»)
Puedes encontrar el código que hace esto aquí.
Cuando lo ejecutes en producción, es probable que te quedes sin espacio en disco si utilizas una sola instancia para almacenar tus artefactos. Por suerte, MLFlow gestiona las conexiones a servicios de almacenamiento de objetos como S3, Azure Blob y Google Cloud Storage con bastante facilidad. Por ejemplo, en el caso de S3, puedes vincularlo a tu servidor de seguimiento al iniciarlo:
mlflowserver\ --backend-store-uri/mnt/persistent-disk\ --default-artifact-root s3://my-mlflow-bucket/\--host0.0.0.0
Asegúrese de que su instancia o estibador ¡Sin embargo, la imagen contiene los permisos necesarios para acceder al bucket!
Carreras anidadas
Pasemos al siguiente paso: supongamos que quieres hacer un seguimiento del rendimiento de varios modelos para luego decidir cuál es el mejor. El seguimiento de los parámetros como lo hacíamos antes servirá, pero para ser aún más ordenados, utilizaremos otra herramienta: carreras anidadas. Como vamos a rastrear un montón de carreras al mismo tiempo, esto las agrupará:
experiment_id=mlflow.set_experiment («Retail Forecast») KNOWN_REGRESSORS= {r.__name__:rforrin [LinearRegression, XGB GBRegressor, RandomForest Regressor, LGBMClassifier]} withmlflow.start_run (run_name=f"retail_prediction_ {current_date}», experiment_id=experiment_id,): [...] for_model_id name, model_classInknown_Regressors.items () :withmlflow.start_run (run_name=f"retail_prediction_ {model_name} _ {current_date}», experiment_id=experiment_id, nested=true,): [...] # Calcular la métrica MSE me=mean_squared_error (y_test, yhat_test) mlflow.log_metric («MSE», mse) # Track featuresmlflow.log_param («Características», x.columns.toList ()) mlflow.log_param («Modelo», nombre_modelo)

Nuestra versión final del código con ejecuciones anidadas tendrá el aspecto como esto.
Consulta de tus resultados
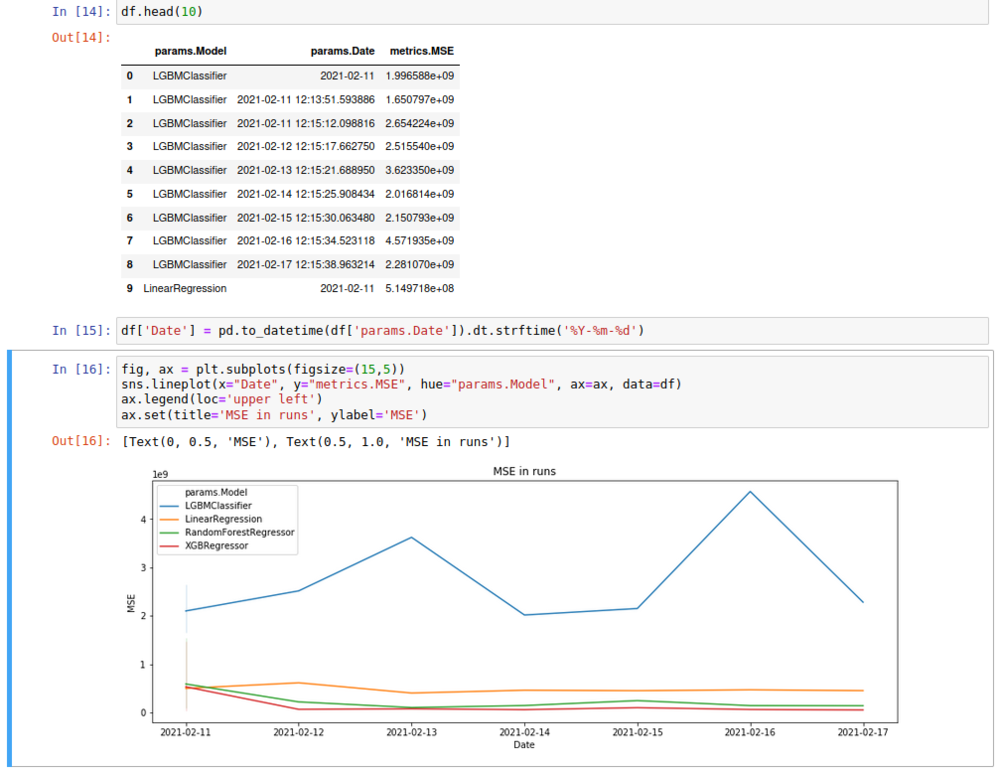
Pero, ¿qué pasa si llevamos un tiempo realizando estos experimentos y ya no es posible comprobar varios resultados a mano en la interfaz de usuario? Podemos usar MLFlowes consultas programáticas y obtenga todos los resultados de forma práctica Marco de datos formato, para que podamos hacer algunos análisis y gráficos sobre él. Solo necesitamos conectarnos a MLFlow como siempre hacemos, y luego buscar nuestro experimento:
mlflow.set_tracking_uri (» http://{username}:{password}@{host}:{port}".format(**mlflow_settings))df=mlflow.search_runs(experiment_ids=experiment_id,)
Entonces podemos trabajar con eso Marco de datos como siempre. Hacemos exactamente eso en nuestro Cuaderno Jupyter.
Discurso de clausura
Después de leer este artículo, deberías poder crear tu propio MLFlow servicio y también comience a rastrear sus propias métricas.
Operaciones de aprendizaje automático (MLOP) es más importante que nunca, y MLFlow es una gran herramienta para hacer precisamente eso. Y no solo es útil para rastreo, sino también para embalaje su código debe ser reutilizable y reproducible sin tener que preocuparse por las dependencias (¡e incluso dockerizar su paquete!) y para desplegando su modelo en diversos entornos. ¡Asegúrate de echarles un vistazo!
Referencias
Documentación de MLFlow. URL
La fuente de la imagen del encabezado es Wikimedia Commons:
Estándares de masa 005: por el Instituto Nacional de Estándares y Tecnología. URL
{kind=link}
Latest Insights

Building a Modern Data and AI Platform on Databricks: Architecture, Migration, and Implementation

Muttdata closes its first investment round to accelerate growth across the Americas

Building a Marketing Data Platform on Databricks: Architecture, Use Cases, and Real Results
