.svg)
5 beneficios de DataOps
Y por qué deberías usarlo


DataOps 101
Si estás leyendo este artículo, es probable que hayas oído hablar de DevOps: un conjunto de buenas prácticas con el objetivo de hacer que el desarrollo y la implementación del código sean más automatizados, robustos y confiables.
Trabajar en el campo de DevOps significa que dedicará la mayor parte de su tiempo a crear herramientas para que usted y su equipo puedan crear un software mejor, como canalizaciones de implementación e integración continuas para que la implementación del software sea fácil y confiable, o Terraform para definir y luego mantener la infraestructura como lo haría con el código.
Pero no se trata solo de construir herramientas: también se trata de un cambio de paradigma. Esto significa que DevOps también consiste en cambiar la cultura de su lugar de trabajo para adoptar los principios de DevOps que hemos mencionado anteriormente.
¿Qué pasa con DataOps? Al igual que la ingeniería de datos consiste en utilizar los principios de la ingeniería de software pero centrarse en el campo de los datos, DataOps aplica los principios de DevOps a los datos. Por supuesto, la aplicación de estos principios a los datos trae consigo sus propios problemas y soluciones únicos: por ejemplo, ser fiable ahora significa poder volver a ejecutar las canalizaciones de datos varias veces y es posible que desee utilizar métodos estadísticos para garantizar la calidad final de los datos.
DataOps significa controlar el almacenamiento y los procesos de sus datos, garantizar su calidad, asegurarse de que estén disponibles para sus usuarios y poder desarrollar herramientas fácilmente con ellos.
En este post te contaremos cómo puedes empezar a aplicar DataOps con algunas de nuestras herramientas favoritas: DEUDA para la gestión y el gobierno de datos, Airbyte para la extracción de datos, comprobaciones de calidad de los datos con Grandes expectativas y el nuestro SOAM para la detección de anomalías.
5 beneficios de DataOps
1. Agilidad y flexibilidad
DataOps adopta prácticas de desarrollo ágiles para permitir a las organizaciones adaptar fácilmente sus canalizaciones de proyectos a los cambios en los datos, las prioridades o los requisitos. El volumen de datos y la complejidad de los sistemas han aumentado a pasos agigantados en los últimos años, por lo que las operaciones de datos son necesarias para mantener la eficiencia y reducir el tiempo de rentabilidad de los procesos.
2. Concéntrate
Los procesos, las metodologías y las herramientas implementados permiten a los expertos en datos evitar las pruebas manuales y la reproducibilidad del entorno, lo que les deja tiempo para centrarse en los objetivos productivos y estratégicos en lugar de en las microdecisiones, el seguimiento de errores o la solución de problemas.
3. Mantenerse relevante
Reducir los tiempos de desarrollo de las canalizaciones de datos y trabajar con un flujo de datos organizado y menos vulnerable a los errores también significa no solo ofrecer información valiosa, sino también hacerlo mientras los datos siguen siendo relevantes. Con los mercados y los contextos empresariales en constante cambio, los datos deben capturarse, transformarse y analizarse lo más rápido posible.
4. Fiabilidad
La estandarización de los procesos de datos, la introducción de prácticas de automatización, la validación y el monitoreo de los datos en todo el proceso y la planificación de las capacidades de reversión en cada etapa de una canalización de datos son las mejores prácticas que reducen los errores. Incluso si los errores logran eludir los controles, es más fácil descubrirlos y descubrir el alcance de sus daños.
DataOps desempeña un papel fundamental a la hora de mantener la coherencia, la fiabilidad y la máxima calidad de los datos. Esto también es clave para mantener buenas relaciones con los clientes, ya que los expertos en datos responden a los problemas y fallos del sistema que puedan surgir.
5. El panorama general
Organizar, optimizar y probar la canalización de datos proporciona mucho más que eficiencia y agilidad. DataOps proporciona una imagen más clara de la comunicación y la colaboración en cualquier organización, así como un mapa claro del flujo de datos en una empresa.
DataOps también puede facilitar la transferencia de conocimientos tanto interna como externamente con las partes interesadas.
Herramientas y prácticas clave
Reversiones
Un error matemático arrastrado a una fórmula, todos hemos pasado por eso. Resulta frustrante que el método tenga sentido y vamos por buen camino con el proceso, pero el resultado final simplemente no es correcto, lo que nos deja con pocos puntos o ninguno. Dejando a un lado los exámenes escolares o universitarios, el mismo concepto se aplica a la hora de crear canalizaciones de datos. Los errores en un solo paso pueden generar valores incorrectos que luego se propaguen en sentido descendente.
Si tan solo pudiéramos retroceder en el tiempo... bueno, más o menos podemos. Las reversiones consisten básicamente en retroceder y encontrar una versión de nuestra canalización de datos en la que las cosas sigan funcionando correctamente. En pocas palabras, si todo se estropea, tienes una segunda oportunidad, es decir, volver a la última fecha de tu memoria en la que todo funcionó sin problemas.
El desafío radica en diseñar un sistema idempotente desde cero. Estos sistemas permiten volver a ejecutar los procesos varias veces, con el mismo efecto cada vez.
La solución es doble. La primera parte es preventiva; parte de la capacidad de detectar errores y volver a lo previsto consiste en organizarse y ser claros. Siempre queremos asegurarnos de que nos hemos tomado el tiempo necesario para pensar y diseñar cuidadosamente nuestro linaje de datos. Cuanto más claro sea nuestro linaje, más fácil será averiguar la extensión del oleoducto afectada por un error.
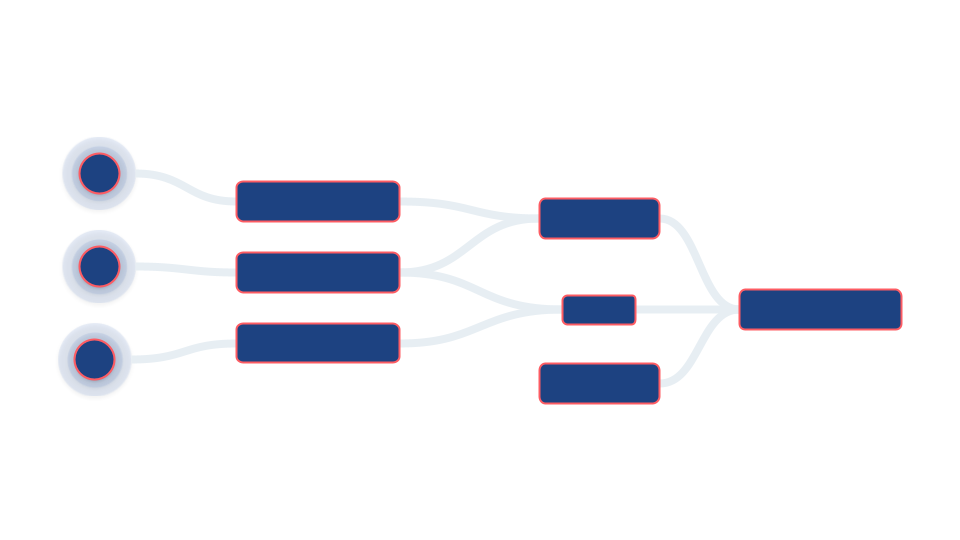
Pero incluso si nuestro linaje es de primera línea, también necesitamos implementar una lógica estándar que nos permita eliminar y volver a procesar los datos antiguos para resolver el problema o los problemas relacionados con la copia de seguridad en clústeres en un estado limpio.
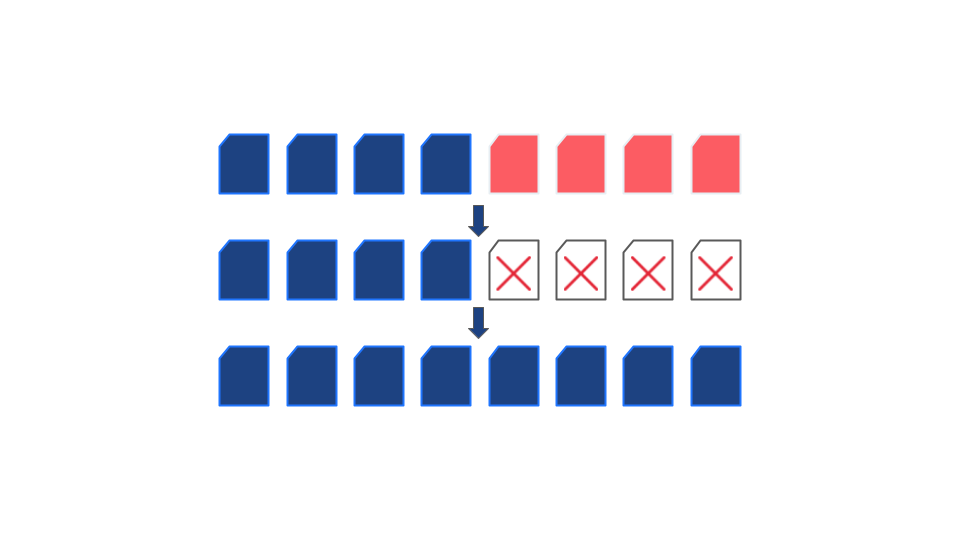
La conclusión es que los sistemas deben pensarse desde el primer día para que sean lo más fáciles de revertir posible, lo que reducirá los costos y aumentará la eficiencia en el futuro si surgen problemas.
Si todo va bien, debería poder identificar los errores y la extensión de los daños de manera eficiente, eliminar los datos defectuosos y devolverlos a un estado limpio y funcional.
Gestión y gobierno de datos
El propósito de la gobernanza de datos es mantener el nivel más alto posible de calidad de los datos de una empresa a lo largo de toda la cadena de datos. Se aplican diferentes prácticas para proteger la coherencia y la seguridad, así como para cumplir con las normativas. Los procedimientos claros y la gestión coherente de los datos dan como resultado una mejora de los esfuerzos de análisis, toma de decisiones y optimización.
La gobernanza también responde a un desafío común: garantizar que las personas adecuadas tengan acceso a los datos correctos. Cuando trabajes con contrataciones temporales externas o con empleados recién contratados, es probable que no quieras que tengan los mismos permisos que tu jefe de tecnología (CTO). Sin embargo, es posible que desees que tengan fácil acceso a datos específicos para que puedan realizar posibles modificaciones o crear vistas.
Recomendamos usar DEUDA: una herramienta que creemos lo incentiva a emplear las mejores prácticas de ingeniería de software para garantizar la calidad de los datos.
DBT simplifica la visualización de la transformación de datos con consultas SQL con plantillas de jinja. Básicamente, es una gran herramienta de democratización con un lenguaje utilizado por prácticamente todos los usuarios (desarrolladores, analistas, propietarios de productos, etc.). Además, también ayuda con los siguientes beneficios:
- Puede realizar pruebas unitarias de las transformaciones en los datos de forma automática
- Puede ejecutar pruebas cada vez que realice una implementación mediante CI/CD, lo que garantiza la calidad de las transformaciones de sus datos.
- Puede realizar cargas incrementales
- Admite el empaquetado de código para reutilizar la funcionalidad existente
- Genera automáticamente documentación para proyectos complejos
- Se puede usar para definir operaciones reutilizables.
Validación y monitoreo de datos
Una gran parte de mantener la canalización de datos limpia, ágil y eficiente tiene que ver con la validación y el monitoreo de los datos. Es fundamental poder detectar los problemas de datos tan pronto como se produzcan y no más adelante, ya que hacer correcciones es más difícil, costoso y lento.
Afortunadamente, existen algunas herramientas y prácticas que facilitan la detección rápida de estos problemas. Por lo general, recomendamos lo siguiente:
Controles de calidad de datos
Los datos incorrectos conducen a malos resultados, lo que a su vez puede llevar a decisiones costosas. Lo más probable es que tenga un buen conocimiento general de su sector y que tenga algunas suposiciones respaldadas sobre lo que puede esperar de sus datos. ¿Por qué no validarlos en función de esas suposiciones antes de trabajar con ellos? Si sus datos huelen mal, o si algo es repugnante o está fuera de lugar, querrá saberlo.
En lugar de utilizar las capacidades integradas de DBT para este propósito, optamos por otra herramienta, Grandes expectativas. Elegimos hacerlo porque proporcionaba una gran cantidad de pruebas integradas, creación de perfiles y un detallado Interfaz de usuario para explorar los resultados de la ejecución de las pruebas. Todo ello con una configuración relativamente sencilla.
Grandes expectativas es una herramienta de código abierto que facilita las pruebas de los canales de datos y la resolución de la deuda de los oleoductos. En resumen, la deuda por oleoductos es lo que ocurre cuando los oleoductos no se han probado, están indocumentados o son inestables debido a malas prácticas.
Una expectativa es una afirmación con respecto a una calidad o característica específica de un conjunto de datos. Por ejemplo, en un conjunto de datos de precios inmobiliarios, una expectativa podría tener un aspecto similar al siguiente:
«Esperamos que los valores de una columna, por ejemplo X, estén entre 100 y 200 pies cuadrados el 65% del tiempo».
Esto, por supuesto, está muy resumido. La conclusión es que la herramienta valida los nuevos datos de entrada comparándolos con nuestras expectativas establecidas.
En lugar de tener que lidiar con datos incorrectos después de su propagación, validar las expectativas antes de este evento te ahorrará mucho tiempo de depuración, así como resultados extraños o infestados de errores.
Detección de anomalías
La relación entre los controles de calidad de los datos y la detección de anomalías es que los controles de calidad de los datos comunes suelen tener valores fijos, es decir, ayer debe haber más de 0 transacciones o el valor total de la transacción de ayer debe ser superior al percentil 5 del total de valores de las transacciones diarias de los últimos 10 días.
Utilizar la detección de anomalías para comprobar la calidad de los datos significa utilizar un modelo de aprendizaje automático que aprende el comportamiento habitual de un KPI y extrapola lo que es un «valor normal» según su historial. Por lo tanto, este valor se ajusta al día de la semana, la hora del día y otras características del KPI. Es decir, si el último martes del mes suele ser el más ocupado en términos de ventas, el umbral para validar el KPI con el control de calidad de los datos será mayor, ya que ese es el patrón que el modelo ML aprendió del pasado.
Para implementar rápidamente este tipo de comprobaciones de datos, una herramienta que recomendamos encarecidamente es Sam (hijo de un chucho), nuestro propio desarrollo interno. SoAm es una biblioteca diseñada por Mutt Data con el propósito de proporcionar un «baterías incluidas» marco para la previsión y detección de tuberías de detección de anomalías.
En línea con las metodologías de desarrollo ágil de Dataops, esta biblioteca busca optimizar nuestro tiempo y productividad cuando trabajamos con datos, lo que permite un código reutilizable para diferentes proyectos.
SOAM se diferencia de otras soluciones al proporcionar un marco de principio a fin para los problemas de previsión y detección de anomalías. Desde la extracción de los datos hasta la presentación de los resultados. En cada etapa, SoAm proporciona componentes listos para usar que reducen el tiempo de desarrollo.
Son Of A Mutt se basa en cuatro características principales:
- Extracción y agregación de datos de cualquier fuente de datos SQL con el marco de datos de Pandas para una fácil manipulación
- Preprocesamiento de tareas como cualquier transformación de Scikit-Learn —como el escalador Min-Max— o incluso tareas personalizadas. Además, puedes combinar, unir y dividir tu DataFrame de Pandas cargado con nuestros módulos integrados.
- Modelos de previsión integrados para ajustar y comparar fácilmente el rendimiento de los modelos.
- Funciones de posprocesamiento para conservar los resultados de las previsiones, detectar anomalías, realizar pruebas retrospectivas de los experimentos, trazar e informar los resultados.
¿Interesado? Por suerte para ti, hemos dedicado una entrada de blog completa a SOAM, sus inicios, sus funciones y usos, incluidos los pasos sobre cómo usarlo. Puedes comprobarlo aquí.
Ingestión de datos
Los resultados son tan sólidos como los datos que los respaldan. Hemos explicado el uso de controles de calidad de los datos y la vigilancia de las anomalías y los errores. Sin embargo, también debemos intentar simplificar y estandarizar la ingesta de datos.
Extracción de datos estandarizada
Trabajar con grandes conjuntos de datos de una variedad de fuentes de datos diferentes puede resultar difícil. Implica muchas horas de programación: establecer conexiones entre diferentes fuentes con diferentes formas de consultar sus datos, trabajar con formatos específicos y muchísimas otras diferencias pequeñas, aunque laboriosas y laboriosas, que conllevan mucho trabajo.
La carga de este arduo trabajo recae en los ingenieros de datos responsables de crear y mantener los procedimientos de ETL. Su configuración no solo lleva mucho tiempo, sino que cada vez que los usuarios de su conjunto de datos encuentran casos de uso que no están contemplados, los ingenieros de datos tienen que crear manualmente un nuevo trabajo de ETL.
Facilitar la extracción de datos con Airbyte
Estas herramientas proporcionan conectores estandarizados para una gran variedad de fuentes de datos, como bases de datos relacionales de PostgreSQL o MySQL, colecciones de MongoDB, confirmaciones de Github, tareas de Asana, tickets de Zendesk, Google Analytics y Facebook Ads, así como muchas herramientas de CRM y seguimiento de usuarios.
Nuestra práctica recomendada es activar los trabajos de extracción de datos con programadores modernos como Airflow. Por lo general, intentamos estandarizar el uso de conectores preexistentes de Airbyte o desarrollar las nuestras propias siguiendo sus convenciones.
Nuestras soluciones con estas herramientas son FIELTRO (Extraer, cargar, transformar) en lugar de ETL. Los datos extraídos se cargan instantáneamente como datos sin procesar en su destino, lo que crea una fuente única de verdad. Gracias a que el costo del almacenamiento, el procesamiento y el ancho de banda son increíblemente asequibles gracias a los servicios en la nube como AWS, los datos sin procesar se pueden almacenar, lo que permite a los analistas de datos y a los profesionales de BI crear cualquier transformación que deseen. ¡Lo mejor es que podrán usar herramientas que ya conocen, como SQL, para transformar estos datos! No es necesario que un ingeniero de datos cree un nuevo procedimiento de ETL cada vez que se necesite una nueva visualización.
Implementación de DataOps con ClassDojo
Empezamos a trabajar con Clase Dojo a finales de 2020, para quienes no estén familiarizados con su trabajo, ClassDojo es una plataforma de comunicación escolar que los profesores, los estudiantes y las familias utilizan todos los días para construir comunidades unidas al compartir lo que se aprende en el aula a través de fotos, vídeos y mensajes.
ClassDojo se enfrentaba a un oponente desafiante, deuda técnica. Su plataforma de datos actual tenía problemas de ETL, procesos de extracción duplicados, problemas de ingestión de datos y una falta general de capacidad de prueba, ya que no se supervisaba en las tablas de entrada y salida.
Esto significaba que rastrear los errores e identificar su impacto no era una tarea fácil y, si se detectaban, no existían procedimientos de reversión automatizados para corregirlos de manera ágil.
Para resolver estos problemas, Mutt Data comenzó por implementar Airflow para administrar sus canalizaciones de datos, reemplazar su planificador de flujo de trabajo anterior por algo más sólido y escalable y preparar el campo de juego para implementar las siguientes mejores prácticas de DataOps basadas en la pila de datos moderna:
- Uso Flujo de aire Plantillas de DAG para simplificar la creación de flujos de trabajo basados en DBT que son idempotentes de forma predeterminada para permitir un reprocesamiento más sencillo y tienen operaciones de reversión definidas de forma predeterminada por tabla.
- Configuración Airbyte como solución estándar para la ingesta de datos sin procesar
- Uso DEUDA para crear, documentar y probar vistas y tablas.
- Configuración de CI/CD para probar automáticamente las cargas incrementales y los pasos de reversión
- Configuración de la supervisión y la detección de anomalías para datos sin procesar, tablas intermedias y KPI finales.
Trabajar con los equipos de ClassDojo fue una experiencia increíble, los cambios implementados les permitieron aprovechar sus datos, mejorar su plataforma de datos y generar un valor empresarial real. Con el objetivo continuo de mejorar, ClassDojo está formando un equipo de ingeniería analítica para centrarse en la arquitectura y los procesos de datos. Trabajar en sus capacidades abrirá el campo de juego a una variedad de oportunidades de implementación del aprendizaje automático, con las que esperamos poder ayudar.
¿Sigues curioso? ¡Estás de suerte! También puedes escuchar la versión de ClassDojo de la historia en su última entrada de blog: «Cómo creamos una plataforma DataOps».
Bandera a cuadros
Una vez que haya implementado estas diferentes prácticas y herramientas de DataOps, estará listo para comenzar y, si podemos decirlo nosotros mismos, será mucho más ágil. Pero antes de continuar ondeando la bandera a cuadros para indicar el final de esta publicación, aquí tienes algunos objetivos de DataOps a los que deberías aspirar. Una canalización de datos eficiente y correctamente diseñada debería:
- Sea lo más simple posible y facilite a los desarrolladores que no son de ingeniería de datos la creación de nuevos pasos en los procesos de análisis.
- Prepárese para la implementación, los nuevos pasos deben implementarse de manera eficiente sin provocar bloqueos ni problemas de datos
- Considere los posibles errores al implementar herramientas y metodologías de recuperación estandarizadas. Las redistribuciones deben tenerse en cuenta desde el primer día para que los equipos puedan y sepan cómo solucionar los problemas tan pronto como se detecten.
- Sea ágil, las causas de los errores deben poder rastrearse rápidamente: ya sea un DAG, una tabla o una transformación, hasta el propietario de esa implementación.
- Sea preventivo y emplee pruebas tanto en los datos como en las canalizaciones para evitar dañar las funcionalidades existentes.
- Detecte y notifique rápidamente los problemas o anomalías de los datos en toda la canalización de datos
- Esté bien documentado para que los datos sean fáciles de descubrir y rastrear.
Finalizando
En Datos de Mutt tenemos experiencia trabajando en proyectos que emplean técnicas y metodologías de DataOps. ¿Necesita ayuda para implementar estas herramientas en su propio caso de uso? Desde canalizaciones de datos que permiten la reversión hasta modelos de aprendizaje automático sólidos y fácilmente escalables, nos adaptamos a las necesidades de su empresa para desarrollar la solución personalizada que su empresa necesita.
Esperamos que esta publicación te haya resultado útil y, al menos, entretenida. Si te ha gustado lo que has leído hasta ahora, tienes unas increíbles habilidades de desarrollo y te gusta aplicar el aprendizaje automático para resolver desafíos empresariales difíciles, envíanos tu currículum aquí o visita nuestra cuenta de Lever para ¡vacantes actuales de equipos!
Latest Insights

Building a Modern Data and AI Platform on Databricks: Architecture, Migration, and Implementation

Muttdata closes its first investment round to accelerate growth across the Americas

Building a Marketing Data Platform on Databricks: Architecture, Use Cases, and Real Results
