.svg)
Lleve su Modern Data Stack al Siguiente Nivel
Cómo utilizar la gestión de metadatos para que sus datos sean útiles


Volviendo a las Modern Data Stacks
En nuestro primera entrada de blog sobre Modern Data Stack, explicamos los ingredientes principales necesarios para construir uno. Si ya lo has hecho, se puede decir con seguridad que ya tienes el cálculo y el almacenamiento de enormes cantidades de datos prácticamente resueltos. Después de todo, se basan en tecnologías de nube fácilmente escalables.
Las Modern Data Stack nos permiten ofrecer datos de toneladas de fuentes diferentes. ¿Y por qué no añadir más y más si la pila lo puede gestionar? Siguiendo esa línea de pensamiento, agregar más fuentes de datos significa más usuarios, cada uno con su propio caso de uso único. ¿Qué podría salir mal?
Los usuarios se apresurarán a resolver sus consultas. Pero se enfrentarán a una dura realidad: ¡ni siquiera saben por dónde empezar! Con toneladas de conjuntos de datos entre los que elegir, seleccionar la fuente correcta para consultar se vuelve mucho más difícil. ¿Qué tabla contiene los datos que pueden responder a mi pregunta? ¿Qué significa el cnt_entity_data columna incluso significa?

Los usuarios afortunados encontrarán el conjunto de datos correcto o una persona dispuesta a ayudarlos que haya pasado por los mismos problemas. Llenos de ilusión, lanzan sus consultas. Para su sorpresa, los resultados parecen extraños: ¿vendimos cien coches negativos el mes pasado? Mmm... Icky. Al crear pilas, es habitual centrarse en mantener los datos actualizados en todo momento. Pero, ¿qué pasa con la comprobación de lo que realmente se añade? La mayoría de las veces, los usuarios se dan cuenta de que una columna lleva días rellenándose con valores nulos, lo que estropea las principales métricas empresariales y los KPI. Si tan solo hubiera una forma de mantener limpios nuestros datos...
Imagínese por un minuto que es su pila de datos. Para empeorar las cosas, además de todos los desafíos mencionados, tienes el correo. Es tu infeliz jefe... Se ha filtrado una enorme cantidad de información confidencial. Parece que permitir que todos nuestros usuarios accedan a todos los datos no fue una gran idea...
Todos estos problemas son posibles indicadores de un problema común: crear una pila de datos escalable de forma increíblemente rápida, pero no lograr que esa pila sea útil para los usuarios. La publicación de hoy presentará el descubrimiento de datos, la observabilidad de datos y la gobernanza de datos. Estos conceptos pueden ayudarlo a evitar algunos de los inconvenientes más comunes de crear una pila de datos moderna. Luego veremos cómo se combinan en Catálogo de datos herramientas, que funcionan con metadatos: datos sobre datos.
Detección de datos: ¿Puedo encontrar los datos correctos?
De qué sirve tener toneladas de datos si los usuarios no pueden encontrarlos o no saben cómo usarlos. Al igual que una biblioteca guarda los libros etiquetados, ordenados y fáciles de encontrar, lo mismo puede hacerse con los datos.
Esto es lo que Descubribilidad de datos se trata de: etiquetar datos para que los usuarios puedan entenderlos y encontrarlos fácilmente. Poder agregar una explicación a una columna y etiquetar tablas para hacer una búsqueda rápida y filtrar nuestros datos por tema y fuente. Además, también es posible comprobar qué usuarios utilizan más datos específicos. ¡Siempre es una buena idea conocer a los expertos que pueden ayudarnos en caso de apuro!
Sin embargo, la capacidad de descubrimiento de datos no se limita a los datos. Las consultas, los paneles de control y los debates también son activos importantes. Al almacenar estos recursos y facilitar su búsqueda, es posible reutilizar el trabajo realizado por los compañeros de equipo.
Con Data Discoverability, los usuarios ahora pueden encontrar los datos correctos y los propietarios de esos datos pueden comprobar las consultas principales y las columnas más utilizadas.

Observabilidad de datos: ¿puedo confiar en mis datos?
¿Puede confiar en sus datos? ¿Están sus datos en buen estado? ¿Se pueden utilizar? ¿Es seguro actuar en consecuencia? Estas son algunas de las preguntas a las que responde Data Observability.
En resumen, la observabilidad de datos se refiere a las mejores prácticas aplicadas para comprender si los datos ingresados a los sistemas están en buen estado. ¿El objetivo principal? Descubrir los problemas antes de que tengan un impacto negativo en las personas que utilizan esos datos.
Y no se trata simplemente de averiguar si se puede confiar en los datos, sino de hacerlo en tiempo real. Una de las ideas en las que se basa la observabilidad de los datos es analizar el estado de los datos y su flujo para detectar problemas antes de que los datos sean realmente necesarios, solucionando dichos problemas de manera eficiente y oportuna.
Entonces, ¿por qué es relevante? El quid de la cuestión es que los datos incorrectos pueden tener altos costos. Las decisiones mal informadas o los períodos prolongados en los que los datos simplemente no funcionan (lo que también se conoce como tiempo de inactividad) pueden tener un impacto negativo en las organizaciones que se basan en los datos. Pueden surgir varios problemas debido a datos inexactos, erróneos o incluso ausentes.
De cualquier manera, la observabilidad de datos puede ayudar a las empresas a mantener su pila de datos moderna funcionando sin problemas al mejorar la calidad de los datos y prevenir problemas al descubrirlos a tiempo. Como resultado, la credibilidad de los datos y de los equipos de datos aumentará dentro de la organización. Sin embargo, estábamos hablando de Modern Data Stack, ¿verdad? Entonces, ¿cómo se relaciona la observabilidad de datos con el tema principal de la publicación?
La observabilidad de los datos desempeña un papel clave en el buen funcionamiento de la pila de datos moderna de una empresa. Es posible que haya elegido todas las herramientas y las mejores prácticas adecuadas, pero si no están integradas correctamente y el petróleo que se utiliza no es de alta calidad ni fluye fácilmente, el conjunto no proporcionará los resultados deseados.
Gobernanza de datos: ¿Cómo se administran mis datos?
Al final del día, los datos son producidos, consumidos y utilizados por las personas. Para cada conjunto de datos, es importante entender de qué equipo forma parte propietaria, quién ha leído y quién ha escrito acceso, y lo que cada plazo utilizado junto con los medios de datos. ¿Esto es lo que Gobernanza de datos se trata de administrar sus datos y evitar el caos.
Los procesos deben ser claros: ¿a quién debo pedir permiso para acceder a un determinado activo? Si no hay un proceso claro para hacerlo, una persona podría quedar bloqueada innecesariamente durante un período prolongado.
La gobernanza de datos debería añadir visibilidad a su sistema: ¿quién ejecuta esa consulta increíblemente intensiva en computación? ¿Lo hacen de forma malintencionada o no quieren hacer daño?
Y no se sabe qué podremos hacer con los datos a medida que la tecnología siga progresando. En nuestra imaginación, el cielo es el límite. En el mundo real, necesitamos normas y directrices de privacidad. Estos ejemplos podrían ser el GDPR y la CCPA. Para hacer frente a los problemas relacionados con el cumplimiento y la lucha contra el abuso, los equipos deben implementar un control detallado de las políticas relacionadas con el acceso y el almacenamiento de los datos.
Solo algunos usuarios necesitan acceder a información confidencial para sus actividades diarias. La mayoría de los usuarios solo necesitan un subconjunto de datos. Por este motivo, la asignación de funciones y permisos específicos a diferentes usuarios es clave para lograr una gobernanza adecuada de los datos.
La solución: ¡Es hora de obtener un catálogo de datos!
Nunca dijimos que los datos fueran sencillos. Por lo tanto, queremos datos en los que podamos confiar, que podamos validar y gobernar. Necesitamos una solución que permita la administración, el seguimiento y la comprensión de los datos. ¿La respuesta? Bueno... más datos, por supuesto.
En los últimos años, ha habido un aumento en las herramientas que pueden resolver estos problemas: el catálogo de datos. Piense en ellas como una forma de organizar mejor sus datos. Están impulsados por metadatos: datos sobre datos.
Imagine una tabla que contenga los resultados de un experimento de aprendizaje automático a lo largo del tiempo. Hay más información en esta tabla de la que puede ver en sus filas. ¿Qué conjunto de datos o servicios se utilizaron como entrada para el experimento? ¿Qué equipo está a cargo de este sistema de aprendizaje automático? ¿La última ejecución se ejecutó mediante programación o de forma manual? ¿Quién consume esta tabla?
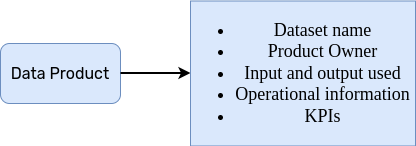
Los metadatos están en todas partes, en un documento, en un canal de Slack, incluso en nuestros pensamientos. Solo hay que insertarlos en un sistema realmente escalable y resiliente. Recuerde: los metadatos siguen siendo datos. ¡Eso significa que todas las técnicas que conocemos para almacenar datos aún se aplican a los metadatos!
Todas las herramientas del catálogo de datos necesitan un lugar para almacenar los metadatos (normalmente una base de datos relacional). Para ingerir sus metadatos, tendrá que empuja a través de una API o transmisión. En el peor de los casos, tendrás que gatear su fuente para incluir los metadatos en su catálogo.
Ahora que sabe cómo funciona un catálogo de datos, podemos presentarle nuestro favorito: Centro de datos.
Entrar en DataHub
Centro de datos es un 3ª generación Catálogo de datos que permite el descubrimiento, la observabilidad y la gobernanza de los datos del ecosistema de datos de una empresa. Linkedin lo creó de código abierto hace 3 años y se usó internamente durante algunos años más.
Se puede conectar a varios sistemas (bases de datos, almacenes de datos, almacenes de funciones de aprendizaje automático, paneles con gráficos) para realizar un seguimiento de los activos y sus cambios en los metadatos (nuevos modelos, actualizaciones de los modelos existentes, etc.). Es capaz de integrarse con otras herramientas de datos populares, como Flujo de aire Apache o deuda mediante conectores, por lo que es fácil empezar.
Hemos descubierto que es una herramienta sólida que cubre la mayoría de los casos de uso relacionados con la administración de metadatos. ¿No nos cree? Puedes probar DataHub tú mismo desde tu navegador!
Así es como DataHub se enfrenta a algunos de los problemas mencionados anteriormente:
Descubrimiento de datos: busque y comprenda a través de metadatos
Los metadatos nos permiten añadir etiquetas sobre nuestro conjunto de datos y comentarios a nuestros campos. La página principal de DataHub incluye una barra de búsqueda que permite a los usuarios buscar conjuntos de datos, personas y otros activos.
Desde obtener el conjunto de datos correcto para su consulta hasta comprender cómo se calculan los KPI, todo son metadatos.
Observación de datos: comprenda su linaje de datos
Ofertas de DataHub visualización de linaje. Muchos productos de datos consumen datos de diferentes fuentes y, a su vez, estas fuentes consumen aún más fuentes de datos. La visualización del linaje de datos permite a los equipos analizar el impacto de los posibles cambios en los datos. Además, resulta útil para la depuración: un equipo puede simplemente comprobar su linaje de principio a fin para encontrar la causa del problema y quién pudo haberlo introducido accidentalmente.
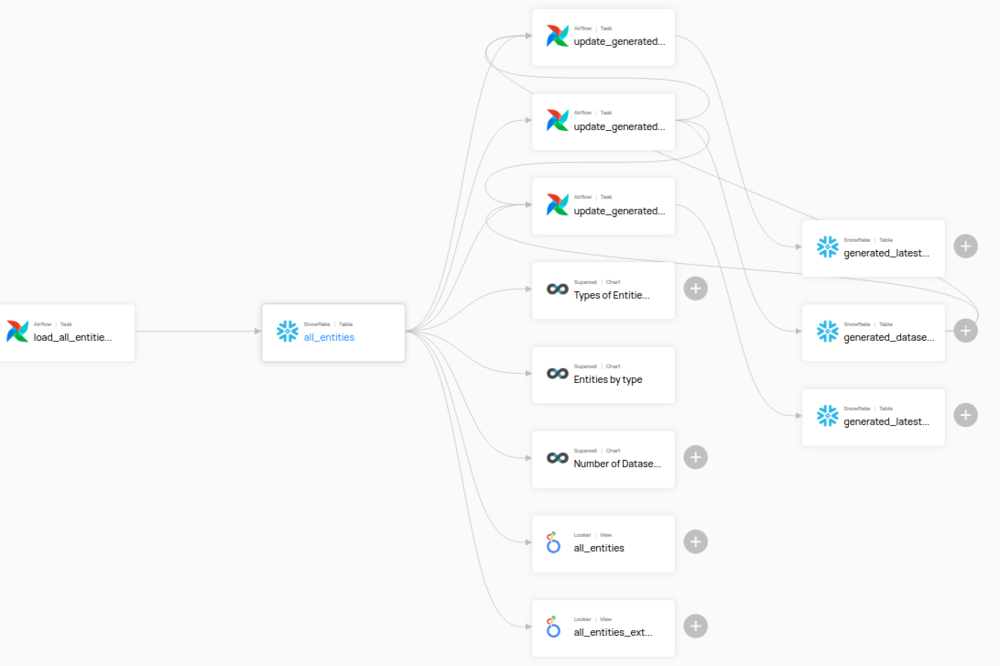
Gobierno de datos: sepa quién está a cargo de qué
Metadatos de versiones de DataHub por defecto. Básicamente, esto significa que cuando se realizan cambios, se almacena la versión anterior de esos metadatos. Esto es fantástico porque es posible auditar un sistema: si a un usuario se le cambian los permisos, aunque sea por un momento, es detectable.
Gracias a las etiquetas de metadatos y su glosario, es fácil establecer un significado claro para los datos, definir quién es responsable de qué y establecer procesos claros de acceso.
¿A quién beneficia la administración de metadatos?
La administración de metadatos beneficia a toda la organización:
- Consumidores de datos: podrán acceder a los datos que necesitan, entender el ecosistema que los rodea e incluso obtener información sobre los paneles o las consultas que otra persona ha realizado y que, de otro modo, no habrían oído hablar.
- Productores de datos: podrán entender a sus usuarios. ¿Cuál es la consulta más popular? ¿Qué equipos utilizan mis datos y cómo?
- Líderes de la organización: Los catálogos de datos le brindan una visión general. Con solo un vistazo, podrán comprender el flujo de datos entre los equipos, quién es responsable de qué activo y sus niveles de privacidad.
Algunas alternativas a DataHub
DataHub es solo una de las increíbles herramientas de catálogo de datos disponibles. Algunas otras que nos ha gustado usar son:
- Abrir metadatos: esta es una herramienta increíblemente poderosa gracias a sus conectores a otras fuentes populares como Postgres, Snowflake y Redshift. También es increíblemente fácil personalizar o agregar soporte para cualquier servicio.
- Amundsen: Puede que Amundsen se quede atrás en la visualización de linajes, pero su funcionalidad de búsqueda es de primera categoría: utiliza un algoritmo similar al de Page-Ranking para organizar los resultados de búsqueda, y las consultas, conjuntos de datos y activos más utilizados aparecen primero. Piense en ello como Google, ¡pero solo por datos!
- Linaje abierto: puede que no sea tan fácil configurar OpenLineage, pero seguro que vale la pena. ¡Tiene montones de conectores para otras herramientas de datos como Airflow, dbt, Great Expectations, Iceberg, Pandas, Spark y herramientas de catálogo de datos como DataHub y Amundsen!
Desafíos de la gestión de metadatos
Esperamos haberlo convencido del increíble uso de la administración de metadatos. Sin embargo, no está exento de desafíos:
En primer lugar, es importante revisar los metadatos caso por caso para decidir cómo estructurarlos. Por ejemplo, puede decidir usar algunos campos comunes entre todos los conjuntos de datos. A la larga, esto podría ser increíblemente limitante. Cada conjunto de datos tiene metadatos útiles para aportar.
Imagina hacer lo contrario. Es posible que usar una estructura de valores clave tampoco sea la mejor idea. ¡Puedes olvidarte de poder validar tu estructura de esta manera! El objetivo de estos ejemplos es el mismo: es importante analizar la estructura correcta caso por caso.
Una buena infraestructura y un mantenimiento adecuado siempre serán de gran ayuda.
Tendrá que decidir para cada fuente de datos si desea usar la transmisión de Kafka o usar la API, y cuál es la mejor manera de hacerlo.
En la actualidad, las tecnologías de transmisión están maduras y son confiables, pero configurar una infraestructura de transmisión desde cero no es una tarea trivial.
En Mutt Data, hemos trabajado en muchísimos proyectos diferentes, cada uno con sus propias necesidades empresariales e infraestructura. Sabemos cómo trabajar con diferentes sistemas de datos y cómo construir grandes infraestructuras en torno a ellos. ¿Quiere impulsar su negocio con datos? ¿Necesita ayuda para crear su sistema de gestión de metadatos? Contáctanos!
Finalizando
Datos de Muttdata puede ayudarlo a cristalizar su estrategia de datos mediante el diseño y la implementación de las capacidades técnicas y las mejores prácticas. Estudiamos los objetivos empresariales de su empresa para comprender qué es lo que debe cambiar y, de este modo, ayudarle a lograrlo mediante una estrategia técnica sólida con una hoja de ruta clara y un conjunto de hitos. Hable con uno de nuestros representantes de ventas en hi@muttdata.ai o echa un vistazo a nuestra folleto de ventas y blog.
Explore los resultados de nuestros clientes a través de nuestro historias de éxito o consulta nuestra Perfil de embrague para opiniones de clientes.
Recursos
- Papá, Shirshanka. «DataHub: explicación de las arquitecturas de metadatos populares». Ingeniería de Linkedin, URL.
- «¿Qué es la administración de metadatos?» Claravina, URL.
- Sitio web de OpenMetadata.
- Sitio web de Amundsen.
- Sitio web de OpenLineage.
Latest Insights

Building a Modern Data and AI Platform on Databricks: Architecture, Migration, and Implementation

Muttdata closes its first investment round to accelerate growth across the Americas

Building a Marketing Data Platform on Databricks: Architecture, Use Cases, and Real Results
