.svg)
Servicio de modelos generativos a escala universal
Y por qué es posible que no desee utilizar FastAPI para ese propósito


Nuevas fronteras
Si eres fan de nuestro blog, sabrás que nos esforzamos constantemente para estar a la vanguardia de la tecnología de inteligencia artificial y aprendizaje automático. En nuestra última publicación técnica, introdujo Stable Diffusion. No por todo el revuelo que lo rodea, ¡sino porque nuestro flamante equipo de investigación ha estado haciendo ✨ magia ✨ con él!
Pero construir sobre modelos de última generación no es suficiente por sí solo si planeas usarlo en la producción. Al igual que otros proyectos de aprendizaje automático, para que este esfuerzo prosperara, tuvimos que desarrollar las capacidades necesarias para atender, monitorear y escalar la infraestructura que servirá como columna vertebral del modelo. Se trataba de un terreno nuevo para nosotros, por lo que fuimos paso a paso. Empezamos a construir desde cero y, a lo largo del camino, aprendimos diferentes alternativas para aprovechar al máximo el hardware disponible para los modelos con uso intensivo de GPU, como Stable Diffusion.
Objetivos de nuestras pruebas
Antes de hacer cualquier punto de referencia, necesitamos saber para qué vamos a optimizar. Al utilizar un modelo como Stable Diffusion, lo más probable es que la GPU sea su obstáculo de hardware, ya sea que opte por proveedores de nube o locales. Por lo tanto, limitándonos a una GPU determinada, queremos obtener el mayor rendimiento posible. Es decir: la mayor cantidad de imágenes por segundo o la mayor cantidad de solicitudes por segundo. Estas dos premisas son similares pero tienen una diferencia matizada: una solicitud puede requerir más de una imagen. Por lo tanto, centrémonos en el RPS partiendo del supuesto de que cada solicitud requiere generar solo uno imagen.
Inicio lento: FastAPI
API rápida es un envoltorio en la parte superior de Starlette, que ha ganado popularidad en los últimos años en el ecosistema de Python. Muchos tutoriales para profesionales del aprendizaje automático enseñan cómo servir sus modelos a través de una interfaz RESTful con FastAPI, pero la mayoría carece de una visión completa del aspecto de los MLOps.
FastAPI se queda corta en muchos aspectos para nuestros propósitos: - Rendimiento - Clasificación: Este punto de referencia es bastante popular, y es posible que notes algo no tan curioso. Los marcos de Python no se clasifican bien. Por lo tanto, el lenguaje elegido ya no es el óptimo. - (Micro) procesamiento por lotes: dado que FastAPI no se creó con el propósito explícito de servir modelos de aprendizaje automático, el microprocesamiento por lotes no es una función integrada. Tendrá que crearlo usted mismo o utilizar un paquete de terceros. - Observabilidad: FastAPI es solo un marco web. Como tal, no incluye funciones que permitan a los equipos de MLOPS/DevOps monitorear el estado casi en tiempo real de una aplicación. - ASGI solo llega hasta sus GPU/s: hardware Lo más probable es que el cuello de botella de tu sistema sea la GPU, por lo que querrás sacarle el máximo provecho. Es necesario realizar algunas optimizaciones en la propia API, pero tendrás que plantearte cómo utilizar la GPU al máximo.
Abordar el rendimiento
Optimizaciones de FastAPI
- No usar
Respuesta de transmisión. En serio. La mayoría los tutoriales en línea devuelven las imágenes generadas usandoRespuesta de transmisión, pero hay varias razones para no. Usando una llanuraRespuesta, observamos mejoras que van desde el 5% para el escenario de un solo usuario y hasta el 60% en la latencia media para el escenario multiusuario. - Utilice el microprocesamiento por lotes. Tuvimos que implementarlo nosotros mismos, pero la idea es que se puedan generar varias imágenes con diferentes instrucciones a la vez (siempre que otros parámetros sean los mismos) y hacer un mejor uso de la GPU. La generación se bloquea, por lo que podemos atender más solicitudes a la vez.
- Aquí establecemos dos parámetros: el tiempo máximo de espera antes de obtener el siguiente lote y el número máximo de solicitudes a recuperar. 500 ms y 8 solicitudes parecían valores predeterminados razonables para empezar.
Trabajadores de Uvicorn
- Utilice
bucle uv. Añadiendouvicorniocomo una dependencia con elestándarextras, obtienesbucle uv, lo que aumenta el rendimiento.
Optimizaciones de PyTorch
- Habilitar cortar la atención para ahorrar en VRAM
- Habilitar memoria, atención eficiente para el rendimiento
- Habilitar Sintonizador automático cuDNN
- Desactivar cálculo de gradientes
- Establecer PyTorch's
número_hilosa 1
Implementación de la observabilidad
Listo para usar, FastAPI no tiene capacidades de observabilidad. Sin embargo, hay muchos paquetes que añaden funciones y se pueden integrar sin problemas.
Prometeo
Prometheus es un conjunto de herramientas de monitoreo y alerta de sistemas de código abierto creado originalmente en SoundCloud. Prometheus recopila y almacena sus métricas como datos de series temporales, es decir, la información de las métricas se almacena con la marca de tiempo en la que se registró, junto con pares clave-valor opcionales denominados etiquetas.
Se usa ampliamente para recopilar métricas como series temporales y consultarlas a través de PromQL.
Usaremos asesor para exportar métricas de nuestros contenedores a Prometheus, exportador dcgm- para exportar las métricas de la GPU y, como veremos más adelante, las métricas directamente desde FastAPI. Para cada una de ellas, utilizamos la predeterminada intervalo de raspado de 15 segundos.
Grafana
Configuramos dos paneles para diferentes propósitos: monitorear la GPU y el contenedor de API.
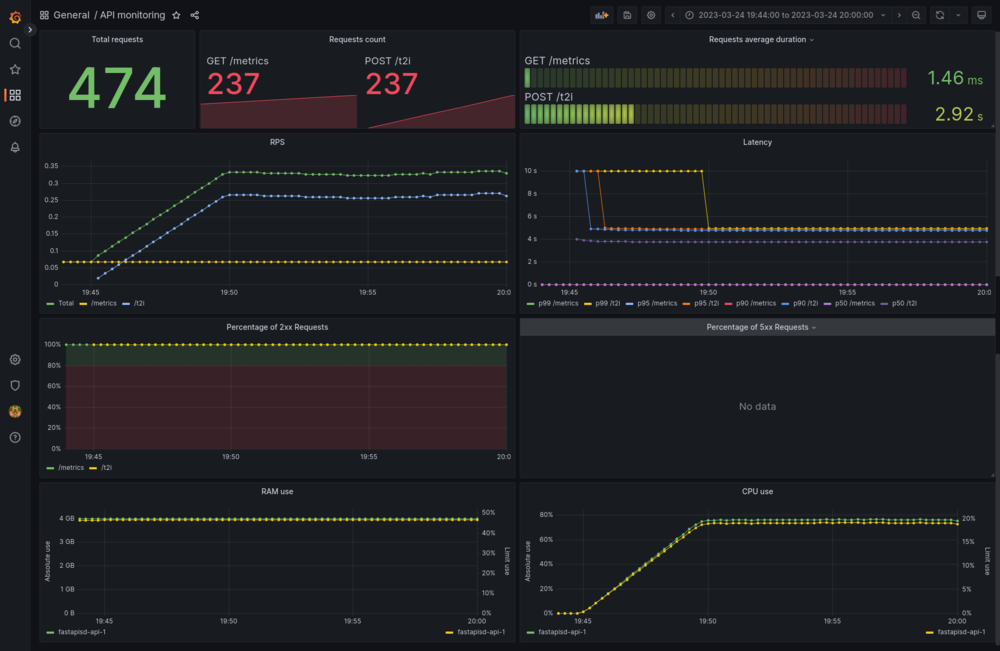
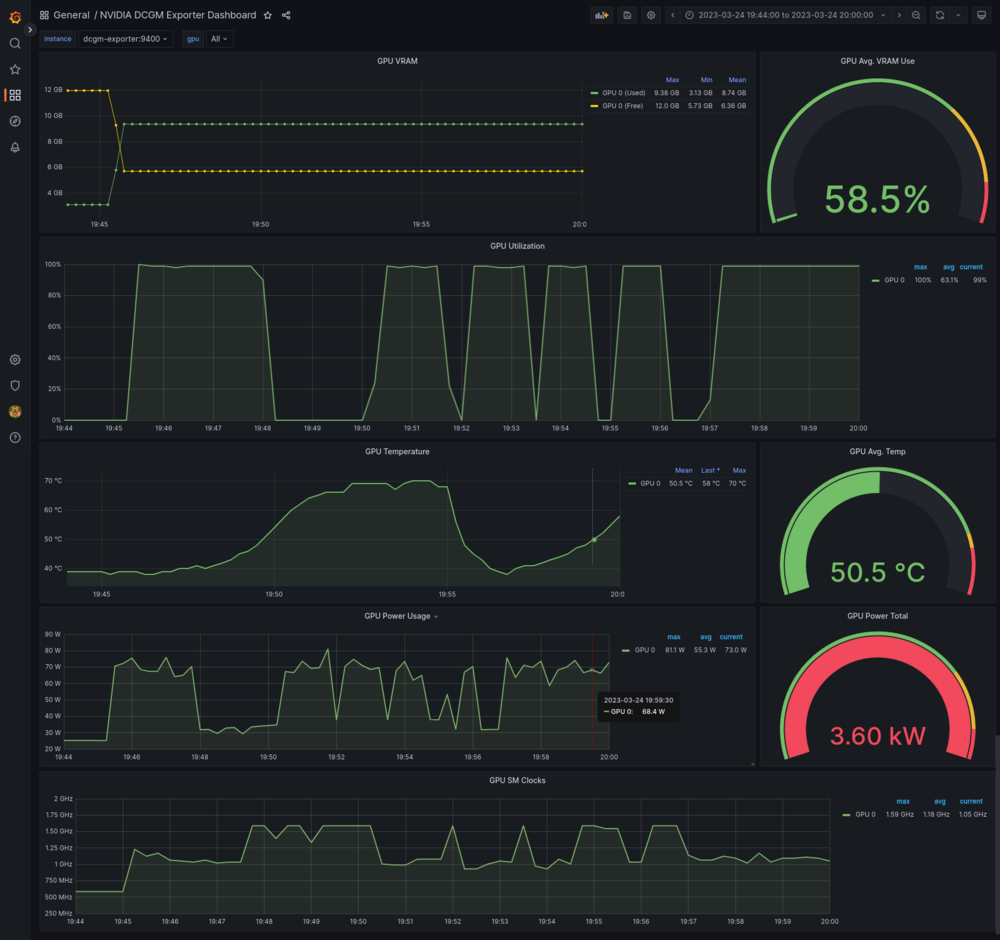
Son imprescindibles para la supervisión en un entorno de producción. Debe ser capaz de darse cuenta de lo que está mal con un vistazo rápido.
Instrumentador FastAPI Prometheus
Usamos instrumentador Prometheus-fastapi para añadir un /métricas punto final que exporta métricas en un formato compatible con Prometheus.
Tuvimos que añadir latencia y peticiones métricas, pero fue muy fácil. Lea el documentos y encontrará la mayoría de los casos de uso explicados.
Pruebas de estrés
Evaluamos varias opciones para probar la API en diferentes escenarios y cargas de trabajo. Necesitábamos configurar fácilmente los escenarios para cada punto final para poder compararlos más adelante.
- Artillería. Gran rendimiento, configurable con código.
- Banco Apache. Fácil configuración, se puede empaquetar en guiones para diferentes escenarios.
- Apache JMeter. Una elección clásica.
- Langosta. Para el pitonista. Fácil configuración. Configurable con código.
Aunque es más adecuado para flujos de trabajo más complejos que el nuestro, optamos por Locust por su facilidad de configuración, escritura de escenarios, obtenemos medidas de rendimiento listas para usar (además de Prometheus) y lo hemos usado en el pasado para varios proyectos.
Langosta
La configuración de cada escenario era similar a la de este fragmento:
ImportRandomFromLocustImportFastHttpUser, TaskClassT2iHighRes (FastHttpUser): @taskdeffetch_image (self) :self.client.post («/t2i», json= {"seed» :random.randint (0,1_000_000), "negative_prompt» :"photography», "prompt» :"pintura digital de bronce (cuervo metálico), autómata aton, completamente metálico, ojos mágicos brillantes, detalles intrincados, encaramado en el banco del taller, iluminación cinematográfica, de greg rutkowski, al estilo de Midjourney, ({steampunk})», "width» :512, "height» :512, "inference_steps» :20, "guidance_scale» :8.2, # «n»: 1,},)
(Que produce imágenes impresionantes, por cierto)
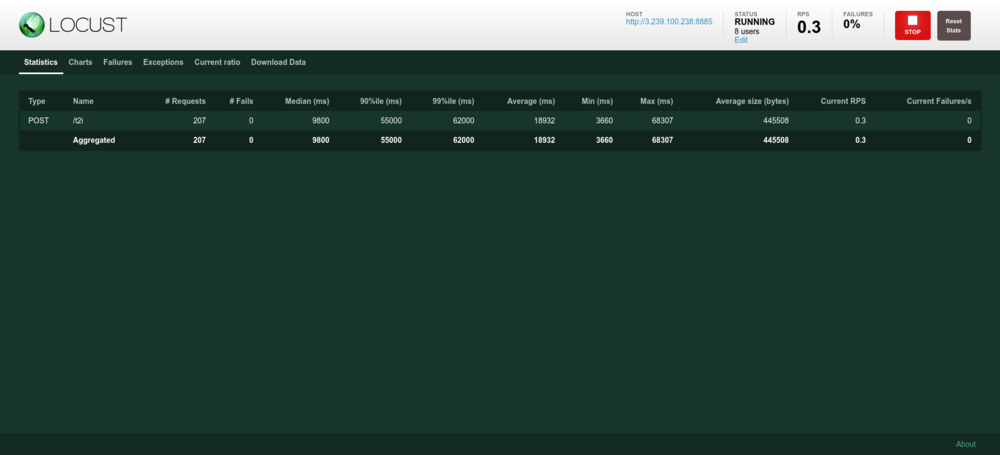
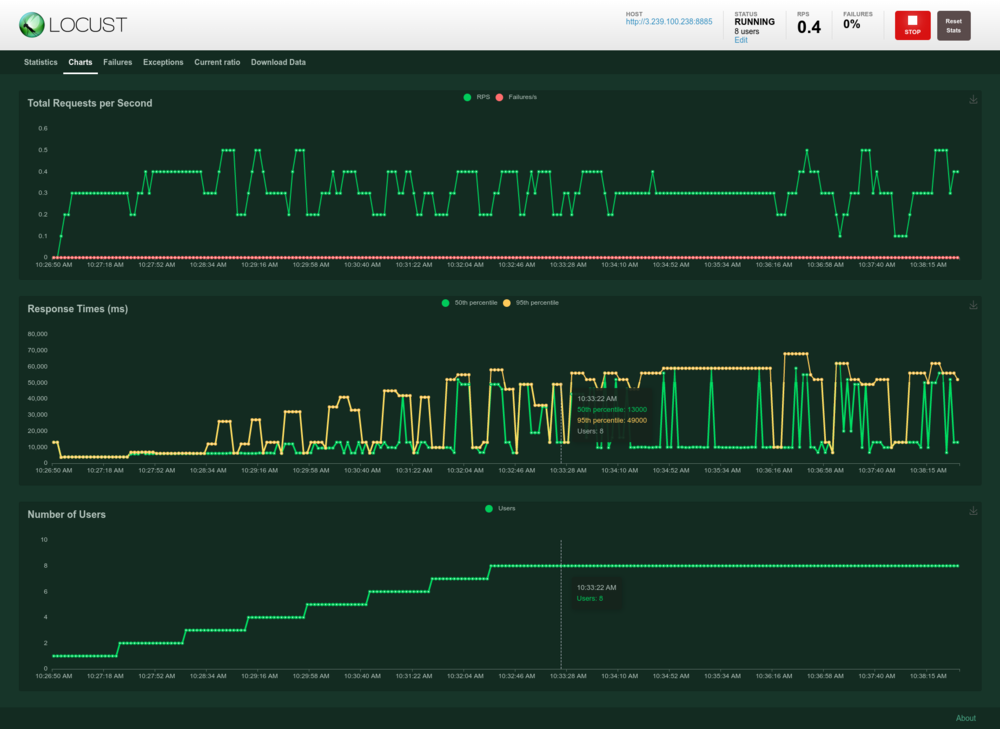
Notarás que obtenemos muchas métricas que ya teníamos en Grafana. Usamos ambas como una verificación doble, pero con grafana/prometheus puedes obtener métricas más estilizadas, como promedios móviles de ventanas de 5 minutos.
Experimentos y resultados
Realizamos todos los experimentos en g4dn.xlarge instancias puntuales proporcionadas por AWS, mediante la AMI de Amazon Linux 2 con controladores de Nvidia. Inicialmente, intentamos realizar la implementación en vast.ai, pero descubrimos que no era posible ejecutar contenedores Docker debido a limitaciones del entorno (Docker en Docker no está disponible). Por lo tanto, no era adecuado para nuestra elección de implementación.
g4dn.xlarge las instancias tienen 16 GB de RAM, 4 vCPU y un GPU Nvidia Tesla T4.
Hay cinco puntos finales para generar imágenes, cuatro de ellos se basan en la combinación de estas características: - Sincronización frente a asincrónica: cuando se utiliza FastAPI, normalmente se definen los puntos finales como asincrónico funciona, pero muchas veces, el servicio subyacente no es asincrónico (por ejemplo, alquimia consulta). Probamos si definir el punto final+servicio como asincrónico las funciones marcaron la diferencia. - Respuesta de transmisión frente a respuesta: Como dijimos anteriormente, nos pareció que era necesario probarlo debido a lo omnipresente que es el uso de un Respuesta de transmisión para devolver imágenes se encuentra en tutoriales en línea e implementaciones de referencia. Implementamos el mismo punto final dos veces, una vez usando un simple Respuesta objeto y otro usando Respuesta de transmisión
Y el quinto es el punto final de microprocesamiento por lotes, que utiliza una cola de prioridad personalizada para ofrecer una cantidad configurable de respuestas al mismo tiempo. Como se ha dicho anteriormente, el tiempo de espera del lote se establece en 500 ms de forma predeterminada y el tamaño máximo del lote se establece en 8. Esto significa que cada 500 ms, si ningún grupo de solicitudes ha acumulado 8 solicitudes, buscamos el grupo con la solicitud más antigua y las atendemos primero. Las solicitudes se agrupan por anchura, altura, pasos_de_inferencia, y escala_guía.
Para todos los escenarios que tenemos 0 fallos, por lo que no se notifican. Las métricas que se muestran aquí provienen de Locust, pero se han revisado comparándolas con los paneles de control antes mencionados.
Escenario 1
Con solo 1 usuario, durante 15 minutos.
{: .table .table-striped .margin-left:auto .margin-right:auto .table-hover .text-nowrap} | Implementación | Solicitudes | Promedio (ms) | RPS | p50 (ms) | p90 (ms) | p95 (ms) | p99 (ms) | |-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------| Streaming (asincrónico) | 218 | 4112 | 0.2 | 4100 | 4200 | 4200 | 4200 | | Respuesta (asincrónica) | 230 | 3912 | 0,3 | 3900 | 4000 | 4000 | 4000 | Streaming (Sincronización) | 226 | 3978 | 0,3 | 4000 | 4000 | 4000 | 4200 | | Respuesta (sincronización) | 236 | 3811 | 0,3 | 3800 | 4000 | 4000 | 4000 | | Por lotes (asincrónico) | 368 | 2439 | 0,4 | 2400 | 2400 | 2400 | 2400 |
Incluso sin las negritas, puedes ver que hay un claro ganador. La implementación del microprocesamiento por lotes, aunque es muy simple, mejora considerablemente tanto la latencia como el rendimiento. Y esto incluso sin intentar optimizar la configuración del microprocesamiento por lotes partiendo de los «valores predeterminados razonables» mencionados anteriormente.
Otra idea clara para este caso de uso es que el uso Respuesta de transmisión perjudica el rendimiento. La implementación asincrónica/sincronizada de los puntos finales y las funciones de generación no supone ninguna diferencia.
Pero, ¿cómo le va a cada implementación con respecto al uso de la GPU? Revisemos algunas métricas obtenidas del panel de Grafana.
{: .table .table-striped .margin-left:auto .margin-right:auto .table-hover .text-nowrap} | Implementación | Uso promedio de VRAM de GPU | |------------------|----------------------------------| Streaming (asíncrono) | 80,6% | 68,8% | | Respuesta (asincrónica) | 60,8% | 59,3% | Streaming (sincronización)) | 59,7% | 71,0% | | Respuesta (sincronización) | 58,5% | 63,1% | | Por lotes (asincrónico) | 75,1% | 42,8% |
Si bien se podría afirmar que es mejor usar la mayor cantidad de GPU, medirlo se vuelve complicado. Por ejemplo, el punto final de sincronización de streaming utiliza más que el punto final por lotes, pero reduce el rendimiento y aumenta la latencia.
Escenario 2
Se podría argumentar que el escenario anterior no es muy representativo de la carga de trabajo que podría enfrentar una API lista para producción. Por lo tanto, creamos otro escenario: 8 usuarios, con una tasa de generación de 0,02 usuarios/segundo (llega un usuario nuevo cada 50 segundos), durante 15 minutos.
{: .table .table-striped .margin-left:auto .margin-right:auto .table-hover .text-nowrap} | Implementación | Solicitudes | Promedio (ms) | RPS | p50 (ms) | p90 (ms) | p95 (ms) | p99 (ms) | |: -------------------: |-----: |------: |------: |------: |------: |-----: |------: |------: |------: -----------: |-----------: |-----------: | | Streaming (asincrónico) | 261 | 21951 | 0,3 | 26000 | 28000 | 34000 | 46000 | | Respuesta (asincrónica) | 269 | 20875 | 0,3 | 9900 | 53000 | 56000 | 69000 | Streaming (sincronización) | 264 | 21618 | 0,3 | 26000 | 32000 | 34000 | 46000 | | Respuesta (sincronización) | 270 | 20729 | 0,3 | 9800 | 56000 | 59000 | 65000 | | Por lotes (asincrónico) | 975 | 5923 | 1.1 | 6400 | 6500 | 6500 | 12000 |
Este escenario proporciona más pruebas de nuestras conclusiones anteriores.
{: .table .table-striped .margin-left:auto .margin-right:auto .table-hover .text-nowrap} | Implementación | Uso promedio de VRAM de GPU | |------------------|--------------------------| Streaming (asíncrono) | 87,7% | 92,1% | | Respuesta (asincrónica) | 84,2% | 91,9% | Streaming (sincronización)) | 90,6% | 93,6% | | Respuesta (sincronización) | 60,2% | 87,7% | | Por lotes (asincrónico) | 71,3% | 80,3% |
La implementación por lotes no tiene ningún obstáculo en la GPU, lo cual es bueno: deberíamos poder seguir escalando a más usuarios.
Optimizaciones de transformadores.
En estas pruebas, probamos el impacto que tenían la activación y desactivación de Memory Efficient Attention (MEA) y Attention Slicing (AS). Usamos la misma rampa ascendente que en el escenario 2: 8 usuarios, con una velocidad de generación de 0,02 usuarios/segundo, durante 15 minutos.
{: .table .table-striped .margin-left:auto .margin-right:auto .table-hover .text-nowrap} | MEA | AS | Solicitudes | Promedio (ms) | RPS | p50 (ms) | p90 (ms) | p95 (ms) | p99 (ms) |: ----|: -----------: |-----: |------ :-----------: |-----------: |-----------: | | ✅ | ✅ | 975 | 5923 | 1.1 | 6400 | 6500 | 6500 | 12000 | ❌ | ❌ | 932 | 6200 | 1 | 6900 | 7000 | 7000 | 7000 | 7000 | ❌ | ✅ | 957 | 6040 | 1.1 | 6500 | 6700 | 6800 | 1300 000 | | ✅ | ❌ | 1131 | 5102 | 1.3 | 5300 | 5800 | 5800 | 8800 |
Y en cuanto al impacto de la GPU:
{: .table .table-striped .margin-left:auto .margin-right:auto .table-hover .text-nowrap} | MEA | AS | Promedio de GPU. VRAM | Promedio de GPU Utilización | |-----|-----|----------------------| | ✅ | ✅ | 71,3% | 80,3% | | ❌ | ❌ | 72,7% | 87,4% | | ❌ | ✅ | 63,9% | 82,5% | | ✅ | ❌ | 49,9% | 83,8% |
En nuestras pruebas, habilitar una atención eficiente de la memoria y deshabilitar la segmentación de la atención obtuvieron los mejores resultados. Por eso usamos esa configuración en la siguiente prueba.
Además, probamos uso del formato de memoria Channels Last para los tensores NCHW, y mejoró aún más estos resultados:
{: .table .table-striped .margin-left:auto .margin-right:auto .table-hover .text-nowrap} | Solicitudes | Promedio (ms) | RPS | p50 (ms) | p90 (ms) | p95 (ms) | p99 (ms) | |----------|----------|----------|----------|----------|1316 | 4383 | 1,5 | 4800 | 5100 | 5300 | 5400 |
Optimización de parámetros por lotes
A estas alturas, tenemos pruebas completas de que incluso las implementaciones de microlotes más básicas pueden mejorar en gran medida nuestras métricas objetivo. ¿Podemos obtener mejores números jugando con algunos parámetros? Intentamos aumentar/disminuir tanto el tiempo de espera del lote como el tamaño máximo del lote. Al igual que en la prueba anterior, configuramos 8 usuarios para que llegaran a una velocidad de 0,02 usuarios por segundo y realizamos la prueba durante 15 minutos.
{: .table .table-striped .margin-left:auto .margin-right:auto .table-hover .text-nowrap} | Tiempo de espera del lote (ms) | Tamaño del lote | Solicitudes | Promedio (ms) | RPS | p50 (ms) | p90 (ms) | p95 (ms) | p99 (ms) | |-------------: |-------------: |-------------: |-------------: |-------------: |-------------: |-------------: --: |-----------: |------: |-----------: |-----------: |-----------: | | 500 | 8 | 1131 | 5102 | 1.3 | 5300 | 5800 | 5800 | 8800 | 250 | 8 | 1121 | 5145 | 1,2 | 5400 | 6000 | 6000 | 9700 | | 1000 | 8 | 1030 | 5599 | 1,1 | 5900 | 6000 | 6000 | 12000 | 500 | 4 | 1083 | 5331 | 1,2 | 5900 | 5900 | 5900 | 5900 | 5900 | 8200 | 500 | 16 | 1051 | 5506 | 1,2 | 6000 | 6100 | 6100 | 12000 |
Nuestra conclusión es que esos «incumplimientos sensatos» iniciales eran... lo suficientemente sensatos. Sin embargo, si tomáramos estos resultados al pie de la letra, realmente estaríamos sobreajuste a nuestro escenario de prueba. Si bien cambiar el tamaño del lote puede hacer que la latencia media empeore entre un 5 y un 10%, eso podría cambiar si cambiamos el número de usuarios.
Conclusiones y próximos pasos
Si bien los resultados iniciales son interesantes, tuvieron un costo. Principalmente en tiempo de ingeniería e implementación de funciones básicas para los modelos de Deep Learning que sirven.
Vamos a tomar Tritón para una próxima prueba de conducción, y tenemos grandes esperanzas en ello. Hay varias otras alternativas a considerar, ya que se trata de un espacio en crecimiento. Después de todo lo que has leído en este artículo, tenemos una base de referencia sólida con la que comparar y una metodología e indicadores de rendimiento claramente definidos que nos servirán de guía.
Latest Insights

Building a Modern Data and AI Platform on Databricks: Architecture, Migration, and Implementation

Muttdata closes its first investment round to accelerate growth across the Americas

Building a Marketing Data Platform on Databricks: Architecture, Use Cases, and Real Results
