.svg)
5 técnicas de implementación para asistentes y agentes de nivel de producción que utilizan IA generativa
Perspectivas y consejos de expertos de la industria


Al diseñar implementaciones de modelos de lenguaje de nivel de producción, con frecuencia surgen varios problemas y sus patrones de solución. A medida que las tecnologías de modelado de lenguajes avanzan rápidamente, mantenerse al día con todos los descubrimientos más vanguardistas es fundamental para ofrecer valor de forma continua a nuestros clientes. Independientemente del caso de uso, ya sea para los asistentes del servicio de atención al cliente, los agentes de automatización de la carga de trabajo o la optimización de la publicidad textual, los siguientes conceptos clave sirven de guía para liderar un proyecto exitoso.
#1 Estado del diseño
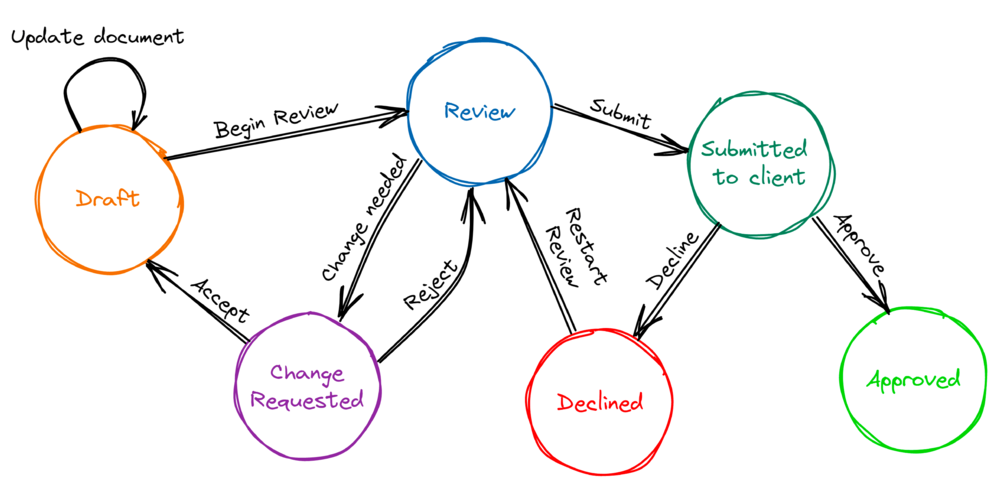
El modelo de red neuronal Transformer no tiene ninguna noción de estado que persista entre las rondas de inferencia. La memoria percibida en modelos como el GPT-3.5 u otros es principalmente un subproducto de la aplicación del mecanismo de autoatención sobre el contenido del contexto de entrada. Solíamos llamar a esta función «estado fantasma» porque parpadea y carece de estructura. El estado fantasma no es lo suficientemente fiable como para mantener el estado para nuestros propósitos, por lo que es necesario encapsular el modelo dentro de una estructura más grande, a la que denominamos «estado externo». ¿Cómo está diseñado?
- Máquinas de estados conversacionales: Desarrollamos una estructura en memoria basada en máquinas de estados para modelar los pasos y el flujo conversacional de cada una de las funciones de asistente o agente.
- Llamadas de backend: A medida que avanza la conversación, y según el estado actual, el modelo lingüístico generará llamadas de backend específicas para actualizar el estado externo.
- Patrones de incitación a los agentes: Se pueden emplear técnicas de incitación avanzadas, como ReAct y Plan&Solve, en tareas complejas para eludir la rigidez del diseño de la máquina de estado. Por ejemplo, pueden ampliar el repertorio de llamadas de backend de manera flexible mediante la composición de llamadas de backend más primitivas.
Al utilizar estos patrones de diseño, es posible desarrollar una implementación predecible y confiable con una tasa de error a la par con la de un operador humano.
Filtro #2

Cuando se desarrollan sistemas que utilizan el lenguaje natural, es fácil caer en la trampa del sesgo de confirmación. Este sesgo llevará a los desarrolladores a creer que todas las entradas posibles o probables del sistema ya se han tratado como casos, lo que normalmente dista mucho de la realidad. Por lo tanto, para crear una solución sólida, es necesario controlar la secuencia textual para reducir el ruido y dirigir la conversación en la dirección deseada. ¿Qué controles se pueden implementar?
- Filtro de entrada: Esta tarea implica filtrar las secuencias textuales o los términos de la entrada que pueden contener texto malintencionado (como los ataques de inyección inmediata) o de la entrada con información que en su mayoría no está relacionada con la función del asistente o el agente.
- Filtro de salida: Esta tarea implica filtrar las secuencias textuales o los términos del resultado que puedan contener contenido inapropiado que pueda representar un riesgo de litigio para la empresa o divulgar información confidencial.
- Técnicas de orientación: Herramientas como NeMo Guardrails y MS Guidance y el uso de técnicas como las secuencias de parada, la recuperación de fichas, la decodificación guiada, las guías de patrones de expresiones regulares, la búsqueda de haces condicionales y otras permiten a los desarrolladores imponer restricciones rígidas al contenido o la estructura de la salida del modelo. La desventaja de usar estas herramientas es que, a menudo, requieren varias llamadas al modelo lingüístico con entradas de contexto incrementales para configurar el resultado, lo que, a su vez, aumenta los costos y la latencia.
El uso del filtrado permite un intercambio seguro de información seleccionada entre el modelo y los usuarios, lo que libera al cliente del riesgo asociado con la generación de contenido inapropiado y también evita que la implementación tenga que gestionar entradas de usuario arbitrarias.
#3 Optimizar

Cada llamada a un modelo lingüístico genera gastos y está asociada a la latencia. El objetivo del cliente es reducir los costos, mientras que el usuario final desea respuestas rápidas. Reducir estas dos variables es, por lo tanto, lo mejor para el cliente, ya que mantener ambas dentro de los límites aceptables determina la viabilidad del proyecto. La utilización de modelos de código abierto es una opción potencial, y a veces la única, para reducir los costos y la latencia en algunas o todas las tareas lingüísticas de la implementación. Por lo general, modelos como ChatGPT o Bedrock ofrecen rentabilidad y producen resultados de mayor calidad para tareas más complejas o poco definidas que requieren un modelo grande para funcionar de manera eficaz. Por otro lado, los modelos de autoservicio pueden ser más adecuados para tareas más específicas que pueden abordarse con modelos lingüísticos más pequeños o para aquellas que implican el manejo de información confidencial. ¿Qué medidas se pueden tomar para optimizar estas variables?
- Condensación rápida: Hay una ingeniería rápida buena y mala. Cada revisión de la solicitud para que sea concisa puede reducir significativamente tanto los costos como la latencia. Además, todo el diseño del sistema debe llevarse a cabo de manera que se minimicen las solicitudes provocadas por la descomposición de las tareas.
- Servicios y marcos de inferencia: Muchos proveedores de servicios, como HuggingFace y MosaicML, ofrecen inferencia como servicio para modelos personalizados. Cuando se utilizan modelos de lenguaje de código abierto, hay varios marcos de inferencia disponibles, cada uno con sus propias ventajas y desventajas, que deben analizarse cuidadosamente para seleccionar el más adecuado para la tarea en cuestión. Un ejemplo notable es la combinación de NVIDIA TensorRT y Triton.
- Procesamiento por lotes: Al ejecutar modelos de lenguaje de código abierto, se debe considerar cuidadosamente la selección adecuada de tamaños de lote para cada tarea, o incluso una estrategia de lotes dinámica, para lograr el mejor equilibrio entre costo y latencia. Por lo general, aumentar el tamaño de los lotes mejora el rendimiento del modelo, pero también aumenta la latencia.
- Almacenamiento en caché: Aquí estamos hablando de dos tipos distintos de cachés: el almacenamiento en caché semántico, una técnica aplicable a todos los modelos lingüísticos, se basa en almacenar en caché las respuestas rápidas y devolverlas cuando se presentan solicitudes semánticamente similares al modelo lingüístico. Esta caché puede resultar especialmente valiosa para tareas específicas, como las preguntas y respuestas de las bases de conocimiento. Otro tipo de caché se conoce como caché KV, que es esencial para que los modelos de autoservicio eviten los costos de complejidad cuadrática al recalcular los valores K y V de cada token nuevo. El almacenamiento en caché de KV es un concepto sencillo, pero normalmente se implementa a nivel de modelo, y no todos los marcos de inferencia admiten el almacenamiento en caché de KV para todos los modelos de lenguaje. La ejecución de grandes contextos sin el almacenamiento en caché de KV suele resultar prohibitivamente costoso tanto en términos de coste como de latencia.
- Inferencia optimizada: Técnicas específicas como la cuantificación, la optimización de gráficos de red, la optimización de la dispersión 2:4 y otras pueden generar mejoras sustanciales en la latencia y el rendimiento, según el modelo y el tipo de carga de trabajo.
- Incorporación de alternativas: El uso de un modelo lingüístico de Transformers no siempre es necesario para todos los aspectos de la implementación, ya que algunas tareas pueden reestructurarse y convertirse en un problema de incrustaciones, que es mucho más rápido y rentable de gestionar.
- Heurística de generación: El uso de una heurística de generación adecuada para cada tarea es importante para lograr un equilibrio entre el rendimiento y la calidad de los resultados deseada.
Una etapa de optimización exitosa siguiendo estas pautas conduce a una implementación de nivel de producción, ya que se puede ajustar para mantenerse dentro de los límites de costo y latencia aceptables.
#4 Buena melodía

Ajustar los modelos preexistentes es uno de los secretos del aprendizaje profundo para producir implementaciones de alta calidad que no frustren a los usuarios del sistema debido a problemas de precisión. Los modelos lingüísticos nos brindan la posibilidad de utilizarlos sin necesidad de formación, incluso para tareas que no requieren mucho esfuerzo, pero esto no significa que los ajustes sean innecesarios o inútiles. ¿Cuáles son las consideraciones clave que hay que tener en cuenta?
- Modelos más pequeños: Como se mencionó anteriormente, los modelos de lenguaje reducido son muy valiosos para abordar tareas más simples con un costo y una latencia mejorados. Los modelos más pequeños suelen requerir ajustes precisos para funcionar con eficacia.
- Datos de alta calidad: Para cualquier tipo de red neuronal, la creación de datos de entrenamiento de muy alta calidad es esencial para un ajuste preciso exitoso que conduzca a una precisión óptima. En el caso de los modelos lingüísticos, ¿cómo podemos generar datos para ajustarlos?
- Corpus externo: Ya sean de código abierto o cerrado, los corpus preexistentes de tipos específicos de texto pueden ser valiosos para ajustarlos, según la tarea.
- Datos de uso real y RLHF (Aprendizaje por refuerzo a partir de la retroalimentación humana): el RLHF implica solicitar comentarios humanos para puntuar los resultados del modelo y luego aplicar el aprendizaje por refuerzo. Los datos de uso reales también son valiosos, ya que permiten identificar las interacciones exitosas del asistente o el agente y, posteriormente, utilizarlos para ajustar el modelo. Según el contexto, también se pueden utilizar las interacciones fallidas.
- Creación manual: La generación de entradas de texto que se asemejen a casos de uso real mediante pruebas manuales o conjuntos de datos creados manualmente en función de reglas suele ser una entrada útil para realizar ajustes. Sin embargo, se debe considerar detenidamente el tiempo necesario para aplicar este enfoque. El uso de secuencias de comandos o la generación programática también pueden entrar en esta categoría.
- IA generativa: El uso de la IA generativa para afinar la IA generativa puede parecer un concepto de Inception (y también suena a sesgo), pero aplicar este método con prudencia puede producir un conjunto de datos seleccionados y de alta calidad.
- __-of-thought__: Si bien no es un procedimiento de ajuste en sí mismo, el uso de La entrada al estilo de pensamiento incorporada en los datos de ajuste para resolver ciertas tareas suele ser una forma de mejorar el rendimiento del modelo.
Una implementación exitosa de modelos ajustados da como resultado una precisión de respuesta significativamente mayor y una experiencia de usuario mejorada, lo que ayuda a cumplir los SLA.
Prueba #5

Probar cualquier tipo de software es esencial como paso previo antes de ponerlo en producción para cumplir con los SLA, y también debe continuar durante el desarrollo. Dado que las interacciones de los usuarios con los modelos lingüísticos son intrínsecamente flexibles y no deterministas, una vez que hayamos descartado las pruebas manuales, que no son sostenibles, nuestra única opción es probar el sistema con un agente de IA generativo. Un agente de este tipo puede moldear y adaptar dinámicamente sus interacciones en función de las respuestas del sistema. Es un software interesante porque, en cierto modo, sirve como contraparte de la implementación. Ha crecido y ampliado sus capacidades para cumplir múltiples propósitos. Estos son algunos puntos clave a tener en cuenta:
- Prueba de funcionamiento: Nuestro objetivo es definir flujos o secuencias de pruebas que abarquen todas las funciones del asistente o agente.
- Entropía de fabricación: Si bien el uso de una temperatura alta cuando se ejecutan modelos da como resultado una gama más amplia de salidas, a menudo no es suficiente. Un enfoque más eficaz consiste en emplear procedimientos de activación específicos para la generación de entropía, que permiten lograr un nivel de entropía mucho mayor en las interacciones del agente de prueba, simulando mejor los casos de uso reales.
- Imita el comportamiento del usuario: Algunas de las pruebas realizadas deberían poder emular el comportamiento de los usuarios basándose en los datos recopilados, especialmente en el caso de los asistentes. El ajuste preciso de los modelos es muy útil para reproducir dichos comportamientos.
- Pruebas continuas: La mayoría de los modelos lingüísticos de los proveedores minoristas se someten a ajustes y ajustes periódicos. En consecuencia, incluso cuando los modelos lingüísticos funcionan con una temperatura cero, las salidas del modelo que reciben el mismo contexto de entrada pueden experimentar una «desviación temporal». Por este motivo, es necesario probar continuamente el sistema para recibir notificaciones tempranas sobre los posibles problemas derivados de esta falta de respuestas. Una estrategia sólida de recopilación de registros facilita la solución rápida de problemas y el análisis de las causas principales para generar mensajes mejores y más estables que sufran menos variaciones.
- Prueba para la generación de datos de entrenamiento: Las entradas y los resultados de las pruebas con modelos son una fuente excelente de datos de capacitación para ajustar los modelos lingüísticos de autoservicio.
Al emplear todas estas estrategias, el cliente puede estar seguro de que las implementaciones proporcionadas mantienen una alta calidad de manera constante, mientras que los desarrolladores cuentan con una herramienta invaluable para probar las funciones y ajustar los modelos.
Conclusión
La IA generativa para textos es la nueva realidad de la mejora de la productividad para empresas y particulares. Puede hacerlo más rápido, puede hacerlo más barato y, a veces, puede hacerlo incluso mejor. En Mutt Data, nos dedicamos a desarrollar soluciones lingüísticas generativas rentables y de alta calidad para impulsar la fuerza laboral del futuro. Analizaremos los objetivos comerciales de su empresa para determinar la mejor estrategia técnica para su caso de uso específico, proporcionándole una hoja de ruta clara y un conjunto de hitos alcanzables. Para obtener más información, ponte en contacto con uno de nuestros representantes de ventas en hi@muttdata.ai o consulta nuestro folleto de ventas y nuestro blog para obtener más información.
¿Estás listo para abordar tu propio conjunto tecnológico? ¡Póngase en contacto con un experto hoy mismo!
Latest Insights

Building a Modern Data and AI Platform on Databricks: Architecture, Migration, and Implementation

Muttdata closes its first investment round to accelerate growth across the Americas

Building a Marketing Data Platform on Databricks: Architecture, Use Cases, and Real Results
