.svg)
Aprovechar la potencia de la generación de inteligencia artificial para crear sistemas de producción robustos
Configuración de un marco para GenAI


Introducción
A estas alturas, probablemente hayas notado un gran revuelo en torno a GenAI. Puede parecer que las posibilidades son infinitas, y es porque lo son. GenAI está allanando el camino para una amplia gama de aplicaciones.
No por nada nos llamamos #DataNerds, por eso durante el último año nos hemos estado haciendo nerds y experimentando con diferentes aspectos de GenAI, cada uno de los cuales ha tenido diferentes niveles de éxito.
¿Nuestra principal conclusión? La mayoría de las capacidades de GenAI no se pueden emplear fácilmente en aplicaciones únicas orientadas al cliente o listas para la producción. Sus resultados aún no están listos; pueden ser impredecibles, propensos a errores, arrojar resultados no válidos o no cumplir con precisión los criterios deseados.
¡Pero no te preocupes! Hay una serie de estrategias para producir resultados valiosos listos para los entornos de producción.
Así que la generación de IA no es perfecta (todavía): ¿qué podemos hacer al respecto?
Imagine una aplicación en la que el modelo debe producir resultados a escala: imágenes, resúmenes de documentos y respuestas a las preguntas de los clientes a través de la interfaz de usuario de un chatbot. Se puede suponer con seguridad que, independientemente de lo que hagamos, algunas muestras no se podrán utilizar para el objetivo previsto.
Entonces, ¿es impresionante? ¿Y qué podemos hacer al respecto?
Bueno, depende, especialmente del impacto de la salida defectuosa inadvertida. Cuanto mayor sea el impacto del error, mayor será nuestro esfuerzo por reducir su frecuencia.
He aquí un ejemplo: si utilizamos un bot para las relaciones públicas en las redes sociales, un «error con un bot» podría afectar gravemente a la reputación de la empresa. Por lo tanto, en este contexto, se podría considerar la posibilidad de incorporar comprobaciones adicionales realizadas por humanos o por otros medios para alcanzar el nivel de error deseado. ¿Cuál es el inconveniente? Este enfoque implicaría un aumento de los costes.
Entonces, ¿es impresionante? Para garantizar que una aplicación sea viable, tanto la frecuencia de los errores como los costes asociados deben estar dentro de un límite razonable.
Decodificando el éxito de GenAI: definición de las tasas de aceptación óptimas
Genial, por lo que la frecuencia de los errores y los costos asociados deberían estar dentro de un límite. ¿Cómo definimos ese límite? ¿Cuáles son nuestros criterios de aceptación? Como ocurre con cualquier otro problema de ingeniería, el primer paso es entender cómo debería ser la solución.
Nuestra solución consiste en entender la tasa de aceptación de los resultados del sistema como un proceso continuo que permite diferentes casos de uso. Cuando se trata de implementar funciones basadas en Genai, identificamos dos umbrales distintos de tasas de aceptación:
- Suscribirse: Esta es la tasa de aceptación mínima requerida para abrir la función a los usuarios, lo que les permite aceptarla o rechazarla. Si la tasa de aceptación cae por debajo de este umbral, los resultados pueden considerarse inutilizables.
- Exclusión: En este nivel, el número de resultados erróneos es lo suficientemente bajo como para que la función esté habilitada de forma predeterminada, y los usuarios que no deseen utilizarla deben deshabilitarla de forma proactiva.
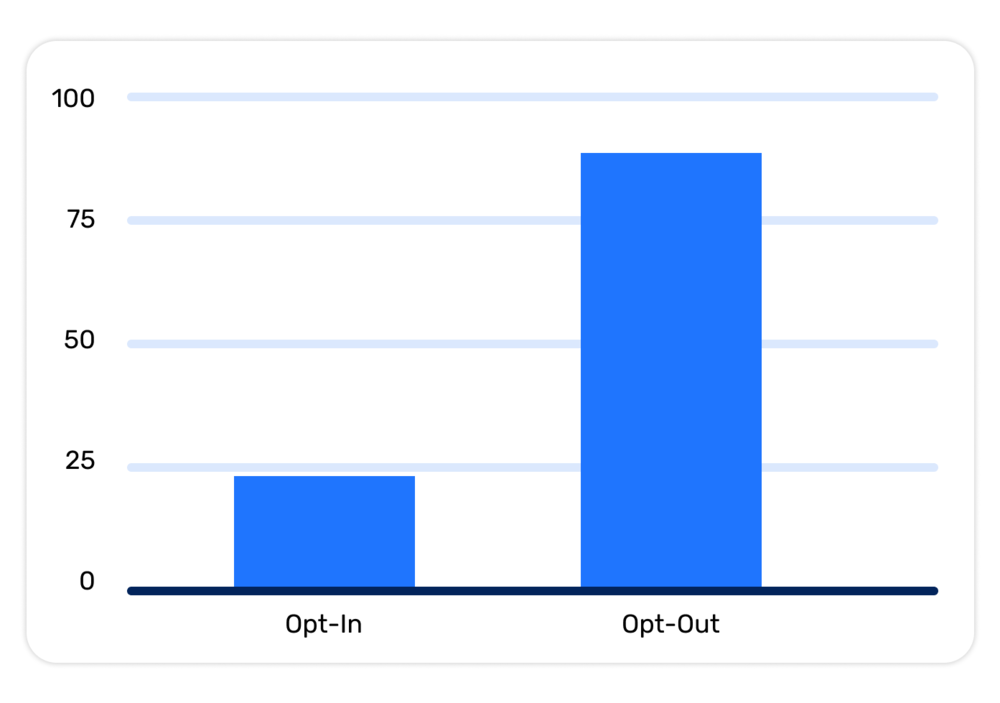
Tenga en cuenta que lo que constituye un resultado válido depende en gran medida de la aplicación y la UX que se diseñen. En algunos casos reelaborar el problema inicial junto con el cliente puede ser la clave para descubrir soluciones exitosas.
El marco de aceptación y exclusión voluntaria en acción
Veamos cómo sería realmente la implementación de un marco de aceptación o exclusión voluntaria para encontrar soluciones viables dentro de un contexto de diseño empresarial y de funciones. Ten en cuenta que los pasos que se enumeran son ejemplos y pueden variar en función de los casos individuales.
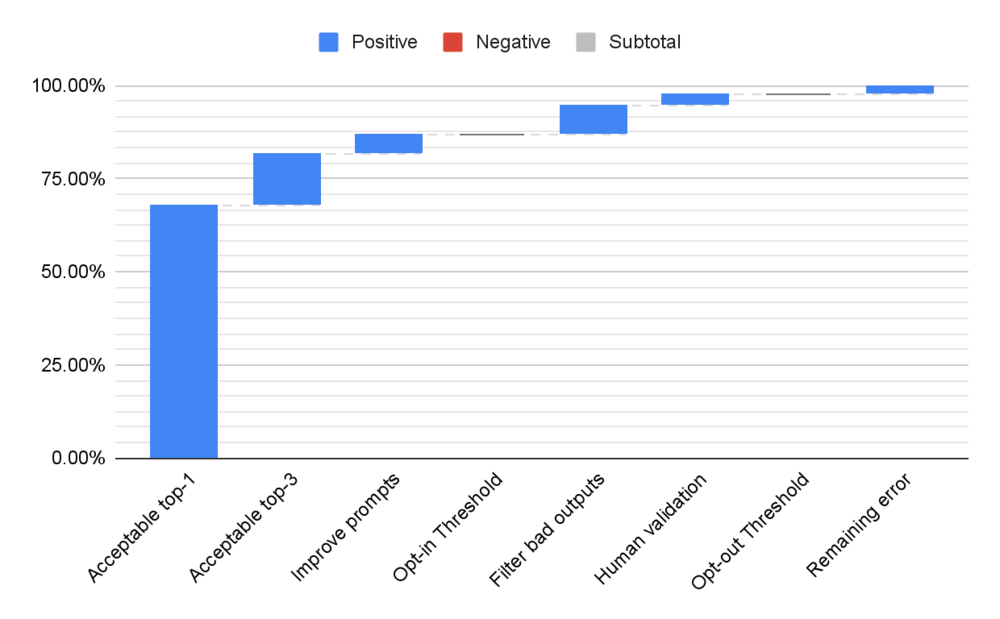
Imagine un sistema de IA de generación que se utiliza para generar descripciones de productos para un sitio web. En este caso, estableceremos el umbral de aceptación en el 85% para los casos de suscripción voluntaria y del 98% para los casos de exclusión voluntaria.
Repasemos los pasos para llegar al umbral de suscripción: 1. Como punto de partida, consideramos solo un texto de salida y lo consideramos aceptable solo para el 68% de los productos de entrada. 2. Observamos que si adaptamos la experiencia de usuario para que el usuario pueda seleccionar una de las 3 imágenes, la tasa de aceptación mejora un 14%. 3. Gracias a nuestro rápido proceso de ingeniería, conseguimos un aumento adicional del 5%, lo que nos sitúa por encima del umbral de aceptación.
Ahora, el umbral de exclusión: 1. Podemos identificar los resultados incorrectos, filtrarlos y sustituirlos tomando muestras de otros nuevos del proceso generativo. Supongamos que esto produciría una mejora del 8%. 2. En este punto, si nos quedamos sin mejoras, el último porcentaje necesario para alcanzar el nivel de exclusión podría consistir en añadir un filtro de moderación humana al proceso. Tenga en cuenta que es posible que esto no sea factible en muchas aplicaciones.
La validación humana: evaluación cuantitativa de costos y beneficios
Para algunas aplicaciones, en las que las muestras «reales» también se someten a moderación (como las imágenes de un sitio web), la validación humana ya forma parte de los procesos existentes. Sin embargo, existe un equilibrio entre el coste de detectar esos errores y el coste de hacer que personas reales comprueben cada envío.
En términos más cuantitativos, podemos pensar en un modelo simplificado para el ingreso neto por unidad basado en las siguientes variables:
- Cg: Costo de generar un producto.
- Ch: El costo de que una persona valide el resultado mencionado.
- Ce: coste medio de un error, independientemente de que una persona lo haya omitido o no.
- Pg: Posibilidades de que el sistema genere una salida errónea.
- Ph: Posibilidades de que el sistema genere un resultado erróneo que luego haya sido validado por una persona.
- R: Ingresos promedio generados por tener un producto correcto.
Ahora vamos a definir el ingreso neto:
$$Ingresos netos = Ingresos totales - Costo total$$
En el caso de un sistema de extremo a extremo sin intervención humana, tenemos:
$$Ingresos totales = R * (1 - Pág) $$
$$Coste total = Cg + Ce * Pg$$
$$Ingresos netos = R - Cg - Pg * (Ce - R) $$
Con la intervención humana tenemos:
$$Ingresos totales = R * (1 - Ph) $$
$$Coste total = Cg + Ch + Ce * Ph$$
$$Ingresos netos = R - Cg - Ch - Ph * (Ce - R) $$
Al comparar estos escenarios, es posible hacer una estimación bruta del beneficio
Algunas advertencias:
- La gravedad de los errores varía; algunos errores, como generar contenido ofensivo o ilegal mediante un generador de imágenes o generar información falsa sobre temas delicados mediante un sistema de generación de texto, pueden resultar más costosos.
- En tareas como la automatización, la incorporación de la validación humana puede frustrar el propósito. ¿De qué sirve un asistente de compras si cada producto requiere comprobaciones manuales antes de llegar al usuario?
- Lo mismo ocurre con los casos de uso de baja latencia para los que la validación humana en tiempo real no es factible.
Finalizando
Hemos abordado algunos de los desafíos de integrar GenAI en los entornos de producción, destacando el difícil terreno de la gestión de errores y las tasas de aceptación. ¡Recuerda! Es crucial lograr un equilibrio entre la automatización y las comprobaciones manuales.
Si te interesa la GenAI (y si has llegado hasta aquí, suponemos que sí), permanece atento a la próxima entrada de nuestra nueva serie: «Explorando las aplicaciones de la generación AI en el mundo real». En las próximas publicaciones, nos centraremos en casos prácticos sobre la generación de imágenes y texto. Además, profundizaremos en las discusiones sobre diversas heurísticas de muestreo destinadas a minimizar las posibilidades de que lleguen a los usuarios muestras incorrectas
Latest Insights

Building a Modern Data and AI Platform on Databricks: Architecture, Migration, and Implementation

Muttdata closes its first investment round to accelerate growth across the Americas

Building a Marketing Data Platform on Databricks: Architecture, Use Cases, and Real Results
