.svg)
Cuándo y cómo refactorizar los productos de datos
Eliminar la complejidad accidental de las infraestructuras de aprendizaje automático


Introducción
Los productos de datos suelen evolucionar en lugar de diseñarse: son el resultado de experimentos exploratorios realizados por científicos de datos que, finalmente, conducen a un gran avance. Al igual que ocurre con los organismos evolucionados, este proceso produce estructuras vestigiales, redundancias, ineficiencias y apéndices de aspecto extraño.
Si bien este crecimiento orgánico es el resultado natural de la fase exploratoria, las presiones de selección que afectan a su producto de datos cambian repentinamente cuando se implementa en un entorno de producción. Este cambio de entorno debe ir acompañado de un rediseño para que pueda soportar grandes volúmenes de datos o, de lo contrario, se derrumbará inevitablemente.
En este artículo, exploramos cuándo (y si) es necesario refactorizar y cuáles son las mejores estrategias para abordarlos.
Síntomas
Emprender una refactorización considerable puede ser una tarea abrumadora (o incluso perder el tiempo), por lo que no se recomienda a menos que sea absolutamente necesario. Lo primero que tienes que hacer es evaluar los síntomas que está experimentando tu sistema y hacer un balance de tu estado deuda tecnológica.
Los síntomas habituales que experimenta un producto de datos son:
- Falta de visibilidad del proceso
- Dificultad para implementar nuevas funciones
- Tasa de iteración lenta del experimento
- Fuentes de datos múltiples e inconexas
- Múltiples puntos de falla irrecuperables, que producen escrituras sucias
- Resultados impredecibles, poco confiables y no replicables
- Procesamiento lento de datos
- Baja visibilidad de los datos a medida que pasan por el proceso
Algunos de estos síntomas por sí solos tienen soluciones relativamente fáciles, pero tener varios de ellos simultáneamente apunta a un problema mayor con el diseño: complejidad accidental.
Complejidad accidental es un concepto acuñado por Frederick P. Brooks, Jr.1, que se refiere a la complejidad innecesaria que acumula un software y que no ayuda a resolver el problema en cuestión.
«La complejidad se debe a la dificultad de comunicación entre los miembros del equipo, lo que provoca fallas en los productos, sobrecostos y retrasos en la programación. De la complejidad proviene la dificultad de numerar, y mucho menos de comprender, todos los estados posibles del programa, y de ahí la falta de fiabilidad. De la complejidad de las funciones proviene la dificultad de invocar esas funciones, lo que hace que los programas sean difíciles de usar. De la complejidad de la estructura proviene la dificultad de extender los programas a nuevas funciones sin crear efectos secundarios».
Esta complejidad accidental es la causa de una sensación demasiado familiar para los programadores: la incapacidad de razonar y comunicarse sobre un sistema. Impide la representación mental necesaria para conceptualizar los sistemas distribuidos y conduce a fijación en problemas más pequeños y fáciles de entender, como los detalles de implementación.
«No solo los problemas técnicos, sino también los problemas de administración provienen de la complejidad. Esta complejidad dificulta la visión general, lo que impide la integridad conceptual. Hace que sea difícil encontrar y controlar todos los cabos sueltos. Crea la enorme carga de aprendizaje y comprensión que hace que la rotación de personal sea un desastre».
Esto también crea un círculo vicioso: dado que el software es difícil de entender, los cambios se superponen en lugar de integrarse, lo que aumenta aún más la complejidad. Es necesaria una refactorización para eliminar la complejidad accidental y se debe rediseñar el sistema de forma que se minimice el aumento de la complejidad en el futuro.
Estrategia
Refactorizar un software que se mantiene activamente puede resultar complicado, por lo que recomendamos la siguiente estrategia.
Comprensión
El primer paso es realizar un análisis materialista del sistema:
¿Qué pretende hacer en comparación con lo que realmente hace?
Esta pregunta es engañosamente difícil de responder, teniendo en cuenta todo lo que hemos hablado sobre la complejidad accidental, pero si se sigue hasta el final se aclararán las contradicciones fundamentales de nuestro sistema, de las que se originan todos los demás síntomas.
Para empezar a resolver este problema, necesitamos analizar las entradas y salidas de nuestro sistema y trabajar a partir de ahí. Es un ejercicio tedioso pero útil, que revelará los caminos que recorren los datos a través de nuestro sistema, dónde se cruzan, se enredan y cuáles nunca se encuentran.
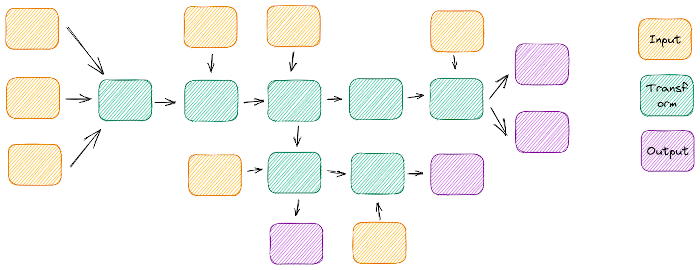
Las entradas y salidas múltiples e inconexas tienden a significar una complejidad accidental
Otra buena forma de entender los entresijos del sistema y sus puntos débiles es intentar introducir un pequeño cambio en él y luchar contra los efectos dominó: ¿el cambio se limita a una sola función o clase o tiene varios efectos en el futuro? Esto es especialmente útil si no estás familiarizado con el proyecto.
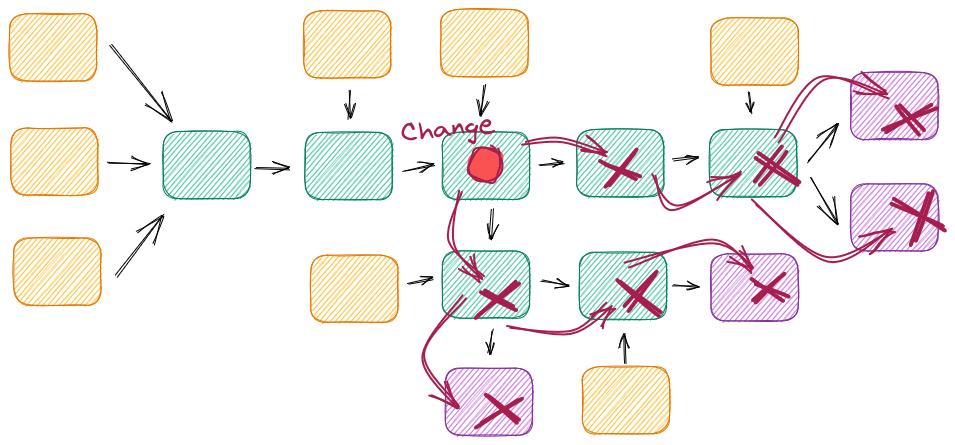
Sin las interfaces adecuadas, un simple cambio puede tener efectos en cascada
Mejoras incrementales
Tenemos que tener en cuenta que este es un sistema productivo que aún necesita mantenimiento, por lo que no podemos simplemente empezar la refactorización desde cero en un repositorio diferente y dejar que la versión anterior se pudra mientras tardamos unos meses en terminar la nueva. Por lo tanto, necesitamos elegir estratégicamente qué partes debemos refactorizar primero, en iteraciones incrementales y conservando la mayor parte del código original que podamos recuperar.
Un buen punto de partida es consolidar todas las entradas en un módulo de «creación de conjuntos de datos» y todas las diferentes salidas en una sola al final. Naturalmente, esto proporcionará puntos de inicio y final para el flujo de datos, aunque aún quede mucho trabajo por hacer a medio camino.

La refactorización incremental bien definida permite nuevos desarrollos entre mejoras
Soluciones
Ahora que tenemos un buen conocimiento del sistema y una estrategia incremental a seguir, podemos empezar a implementar nuestras soluciones.
Desenreda
Hay una tendencia en los productos de datos a tener módulos y funciones con múltiples responsabilidades, debido al hecho de que el código exploratorio evoluciona añadiendo módulos donde se necesitan, pero sin poner énfasis en un diseño general.
En esta etapa, es útil pensar en las tres operaciones básicas de la ingeniería de datos: Extraer, transformar, cargar. El primer paso para desenredar los módulos altamente acoplados es dividirlos en estas tres operaciones básicas (y agruparlos según).
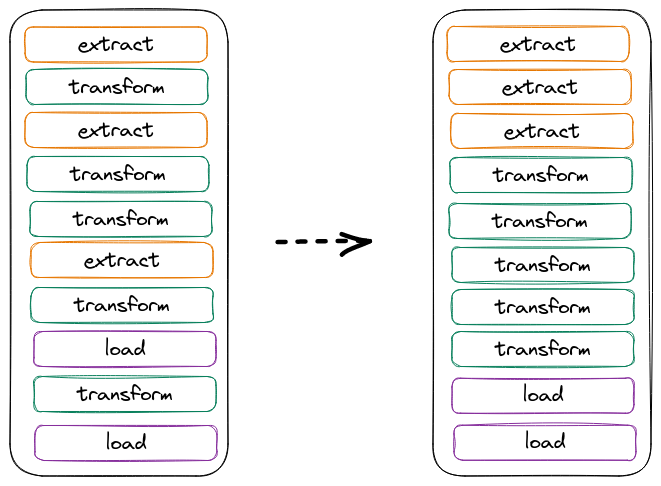
La simple reorganización del orden de las operaciones puede mejorar la comprensión
Podemos abordar este proceso con una estrategia de divide y vencerás: empezar por el nivel de función y clase y, poco a poco, ir reorganizando todo el diseño de esta manera. A medida que avancemos, empezaremos a ver oportunidades para eliminar el trabajo duplicado o inútil.
Modularizar
Ahora que nuestro código está más organizado, podemos empezar a separarlo conceptualmente en módulos. Los módulos deben seguir el principio de responsabilidad única y ser lo más claros y concisos posible con respecto al trabajo que realizan, lo que nos permitirá reutilizarlos al escalarlos.
Los productos de datos suelen crecer poco a poco en función de las exigencias de la empresa. Esto hace que los módulos estén estrechamente vinculados a la lógica empresarial, lo que los hace demasiado específicos o conllevan demasiadas responsabilidades. De cualquier manera, esto dificulta su reutilización y, en consecuencia, aumenta la complejidad accidental y reduce la escalabilidad.
Con esto en mente, deberíamos sentirnos libres de reorganizar los módulos existentes en otros nuevos y más limpios, liberándonos de las restricciones artificiales existentes en el proceso. Es probable que acabemos con clases y funciones más pequeñas que antes, y que sean más reutilizables.
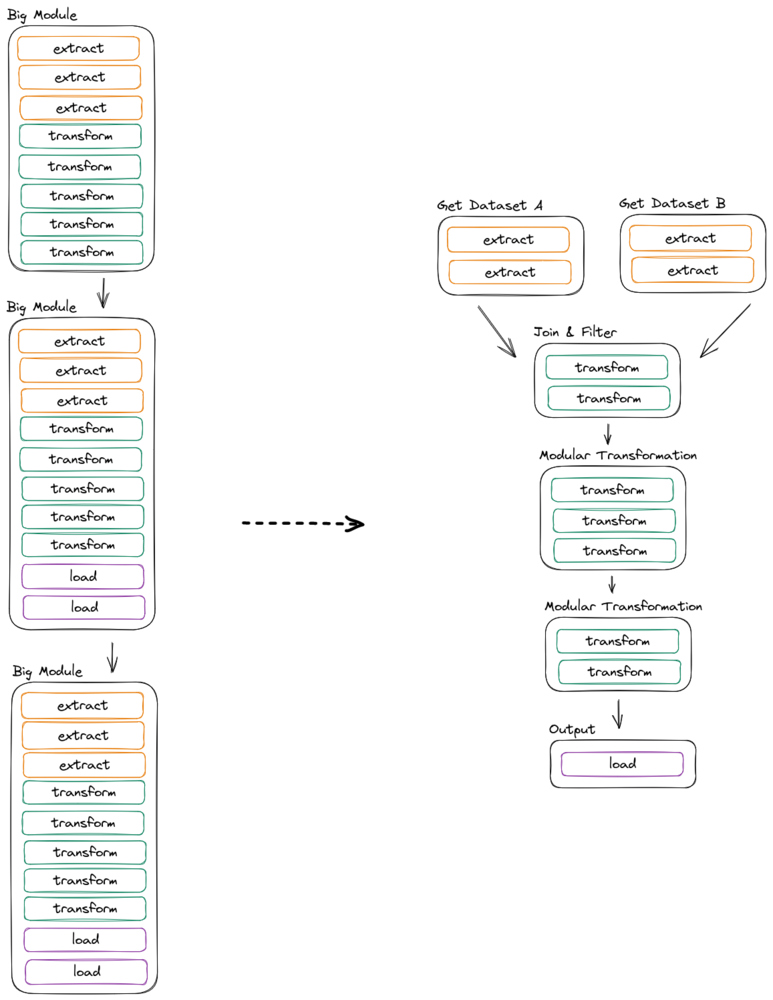
Tener módulos no es necesariamente una buena modularización
El proceso de modularización también mejorará, a través de la abstracción, la forma en que pensamos sobre nuestro código. Ahora podemos reorganizar módulos enteros sin correr riesgos e incluso es probable que descubramos que los procesos que antes estaban estrechamente relacionados se pueden separar por completo en tareas independientes.
Interfaces de diseño
Una vez que hayamos separado conceptualmente cada módulo, podemos empezar a planificar cómo separar la canalización en tareas más pequeñas orquestadas. Para lograrlo, necesitamos definir las interfaces para cada tarea y seguirlas estrictamente.
En las canalizaciones de datos, nos gusta pensar que los datos en sí mismos son la interfaz entre las tareas, ya que siguen la estructura estricta y las restricciones que imponemos a esos datos. Teniendo esto en cuenta, solemos definir las tablas intermedias como interfaces entre tareas y los marcos de datos estructurados como interfaces entre los módulos de la tarea.
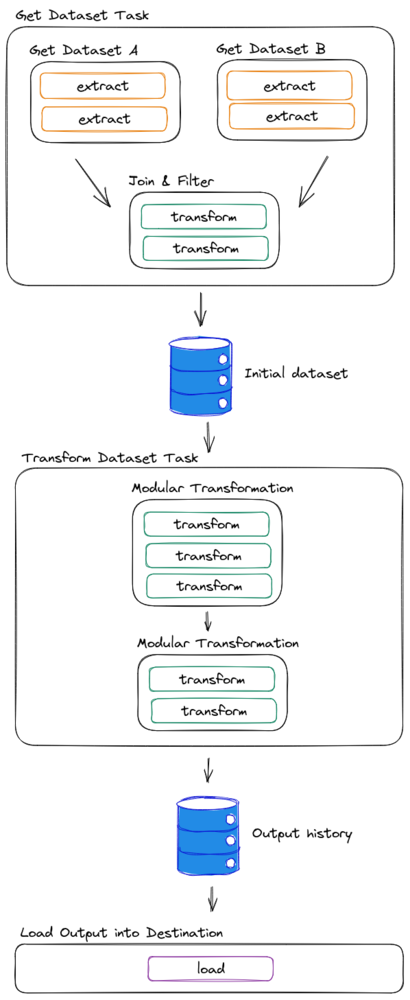
Las tareas independientes deben conservar los datos en algún lugar
Hay varios beneficios de tener tablas intermedias como interfaces sólidas:
- Aplican un esquema entre los módulos.
- Proporcionan puntos de control entre los procesamientos, en caso de que sea necesario volver a intentarlo.
- Proporcionan visibilidad en el proceso y se pueden utilizar para supervisar la calidad de los datos.
- Reducen el consumo de recursos al reutilizar los conjuntos de datos creados
- Proporcionan un conjunto de datos y un historial de resultados para reproducir experimentos o entrenar otros nuevos.
- Las tareas se pueden conectar y usar si se adhieren a la interfaz
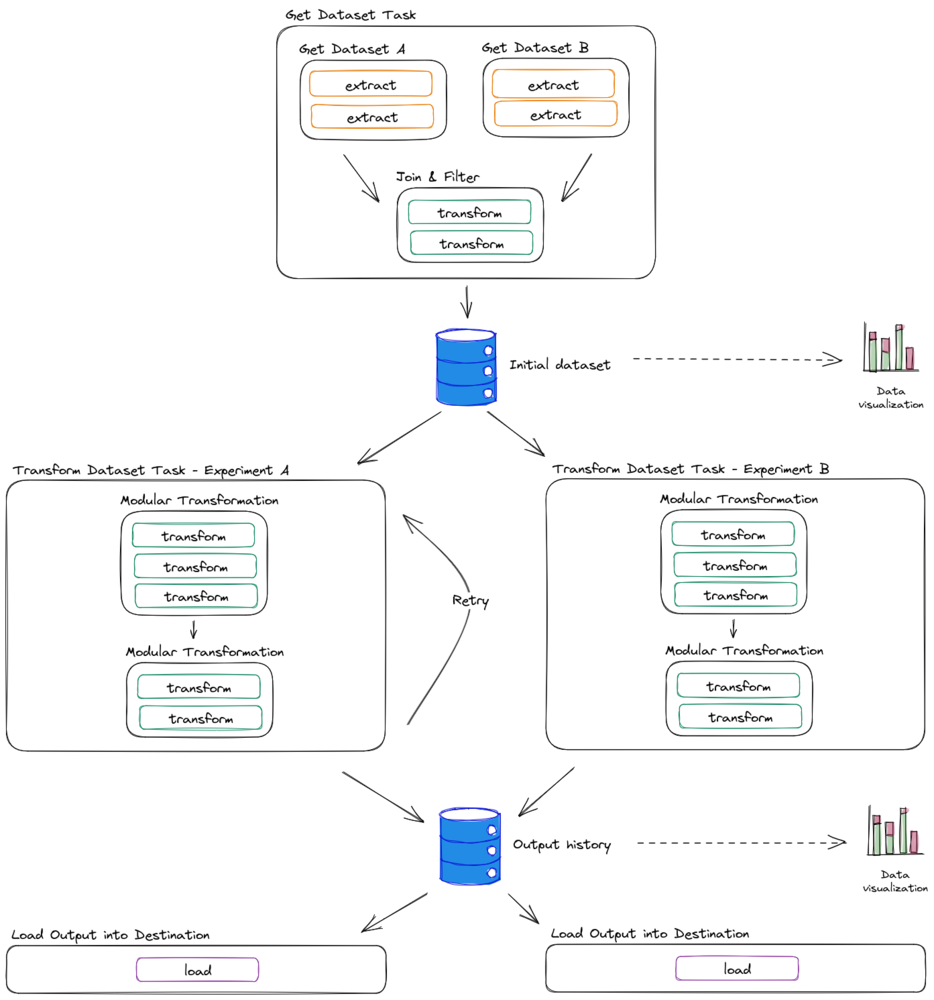
Tener tablas como interfaces abre un gran potencial en el diseño
Optimizar
La optimización en los sistemas de Big Data rara vez proviene de obtener el máximo rendimiento de una línea de código determinada, sino más bien de evitar el trabajo duplicado, elegir las herramientas adecuadas para cada tarea y minimizar la transferencia de datos a través de la red.
Esto solo se puede lograr por completo después de aplicar las soluciones anteriores de esta lista, ya que la modularidad y la comprensión nos permitirán reorganizar el flujo de datos a nuestro favor y tener tablas como interfaces nos permitirá tener una variedad de herramientas entre las que elegir para interactuar con los datos.
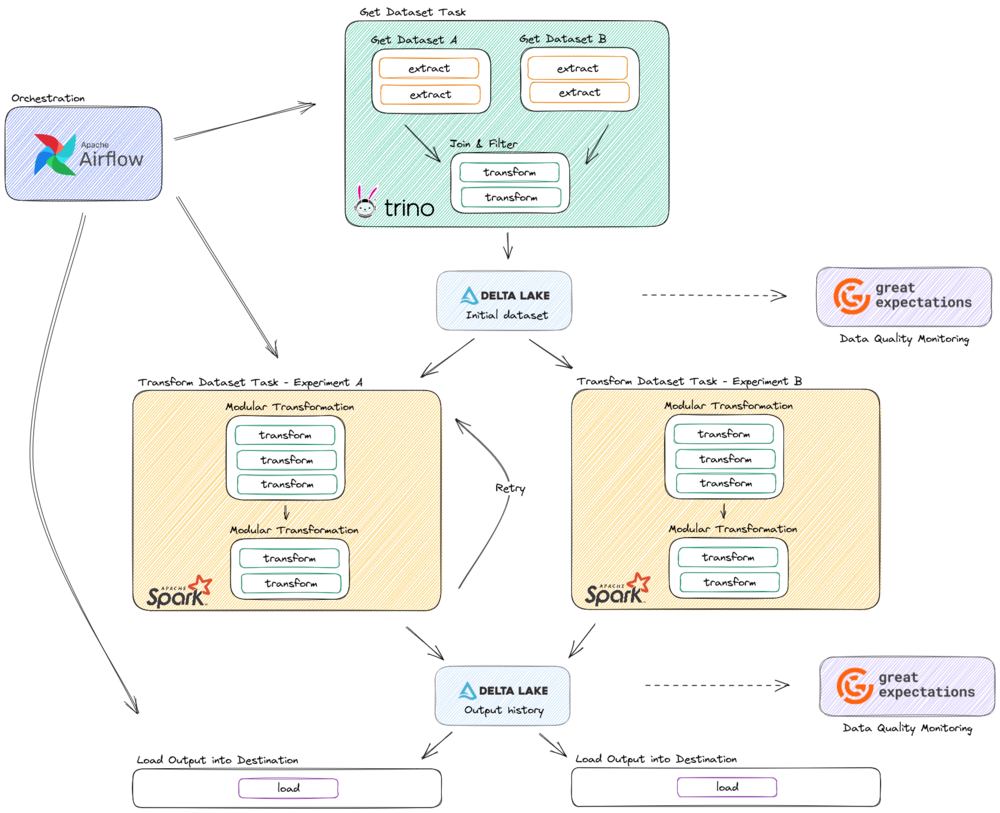
Ejemplo de un diseño refactorizado que muestra diferentes tecnologías para cada tarea
Conclusiones
La refactorización de un producto de datos no es una tarea fácil, pero puede ser muy gratificante si se hace correctamente. Sin embargo, lo ideal es tener en cuenta estas consideraciones de diseño antes de implementar el MVP de Data Science en producción, ya que son más fáciles de implementar antes de esa etapa.
Notas a pie de página
- Frederick P. Brooks, Jr.»No hay fórmula mágica: esencia y accidente en la ingeniería de software« ↩
Latest Insights

Building a Modern Data and AI Platform on Databricks: Architecture, Migration, and Implementation

Muttdata closes its first investment round to accelerate growth across the Americas

Building a Marketing Data Platform on Databricks: Architecture, Use Cases, and Real Results
