.svg)
Así que... Hicimos un robot parlante
Cómo navegar por la interacción de voz impulsada por LLM


👉 ¿Por qué hicimos un robot parlante?
👉 Desafíos
👉 Cómo superamos las dificultades
Introducción: ¿Por qué creamos un robot parlante?
Los LLM están de moda en este momento, con aplicaciones variadas que van desde programar hasta jugar a Minecraft. Probablemente el uso más obvio y directo de esta tecnología siguen siendo los chatbots.
Sí, los chatbots pueden no ser tan atractivos como otras aplicaciones, pero bueno, son realmente útiles. A veces es necesario combinar la PNL con tareas menores; los chatbots de LLM son herramientas muy útiles para ello. Por ejemplo, un servicio de atención al cliente sencillo y la programación de citas. Las interacciones más complicadas aún están fuera del alcance de los LLM actuales.
Sin embargo, hay un inconveniente: ignorando la nueva y brillante multimodalidad, los LLM se comunican a través del texto. Obtienen texto y texto de salida. Esto no es necesariamente adecuado para todas las tareas. Aunque la interacción subyacente sigue siendo la misma, ¡a veces la gente solo quiere hablar con alguien! De hecho, algunos investigación indica que la preferencia del usuario entre la comunicación por texto o voz depende de la tarea y del contexto.
Aún más interesante es que, después de repetidos fracasos a la hora de resolver un problema, las personas suelen preferir interactuar por voz que por chat.
Las llamadas telefónicas suelen ser menos eficientes que los chats. Solo puedes tener uno a la vez y, por lo general, duran más (siempre que las personas respondan a los chats en el acto, lo que probablemente no suceda). La automatización de las llamadas telefónicas puede optimizar los costos. Lo ideal es que las respuestas automatizadas a las preguntas frecuentes y a los problemas comunes permitan a las empresas asignar los recursos humanos de manera más estratégica, centrándose en la resolución de problemas complejos y en tareas de alto valor.
Ahí es donde entramos nosotros. Decidimos abordar este problema haciendo que un bot respondiera a las llamadas telefónicas. Hace poco desarrollamos una PoC que combina la de Symbl Nebulosa LLM con módulos listos para usar para crear un bot parlante. Nuestro objetivo era crear una conversación aceptable con un bot. Te darías cuenta claramente de que se trata de un bot, pero no pretendíamos que pareciera humano.
Desafíos: Qué hace que la experiencia se sienta bien
¡Latencia, latencia, latencia!
La demostración tuvo varios problemas, pero la latencia era una prioridad. Cuando hablas con alguien, esperas que te responda bastante rápido. Tener una latencia baja es crucial para que esto sea viable; de lo contrario, arruina la ilusión de tener una conversación real. Si necesitas esperar 10 segundos para recibir una respuesta, la experiencia no será satisfactoria ni eficiente.
Mantener una latencia baja no solo requiere hacer que el bot sea más eficiente, sino que también limita las soluciones que podemos usar para abordar otros problemas. En otras palabras, no podemos hacer trucos que consuman mucho tiempo para resolver problemas. Calidad de la transcripción Para las conversaciones en tiempo real, necesitamos transcribir continuamente el audio del usuario, lo que requiere un método rápido y fiable para gestionar clips de audio cortos. Si la transcripción no coincide con lo que dijo el usuario, entonces la respuesta del bot no tendría sentido. Si el método de transcripción es lento, alteramos nuestra latencia, lo que afecta a la experiencia del usuario.
Siga las pautas
Los LLM pueden ser impredecibles, por lo que necesitan barreras cuando interactúan con los usuarios/clientes. Deben proporcionar información precisa y mantenerse coherentes con su comportamiento previsto.
Si el bot comienza a hablar de cosas que no están relacionadas con su objetivo, es evidente que no está cumpliendo su tarea. Además, un usuario puede obligar intencionalmente al bot a cometer un error, por lo que también debemos tenerlo en cuenta. No es tan fácil de hacer. Sobre todo teniendo en cuenta que no utilizaremos un LLM personalizado y que cualquier examen minucioso de las instrucciones requiere tiempo. Aproveche la información
Además de simplemente hablar con el usuario, hay algo importante: ¿qué debe lograr el bot? Hay varias direcciones en función de lo que se requiera de él. El punto clave es aprovechar la información relevante durante la conversación. Por ejemplo, si queremos que el bot programe citas, debe conocer las franjas horarias disponibles y evitar seleccionar las no válidas. Si el bot está diseñado para ayudar a los clientes con sus problemas, debe saber cómo ayudar y adaptarse a sus necesidades, o reconocer cuándo no puede ayudar en lugar de proporcionar información irrelevante. Todas estas tareas requieren que el bot interactúe con los datos.
Una breve demostración
Una breve demostración.
Cómo funciona
Sin más dilación, aquí está el flujo de trabajo de nuestra demostración. Para esta demostración, el bot programará una llamada ficticia para hablar sobre los servicios de Mutt Data. Su funcionamiento es muy sencillo (aunque ha requerido algunas iteraciones). Interactuamos con los servicios proporcionados por AWS y Symbl. A continuación se muestra un diagrama de eventos:
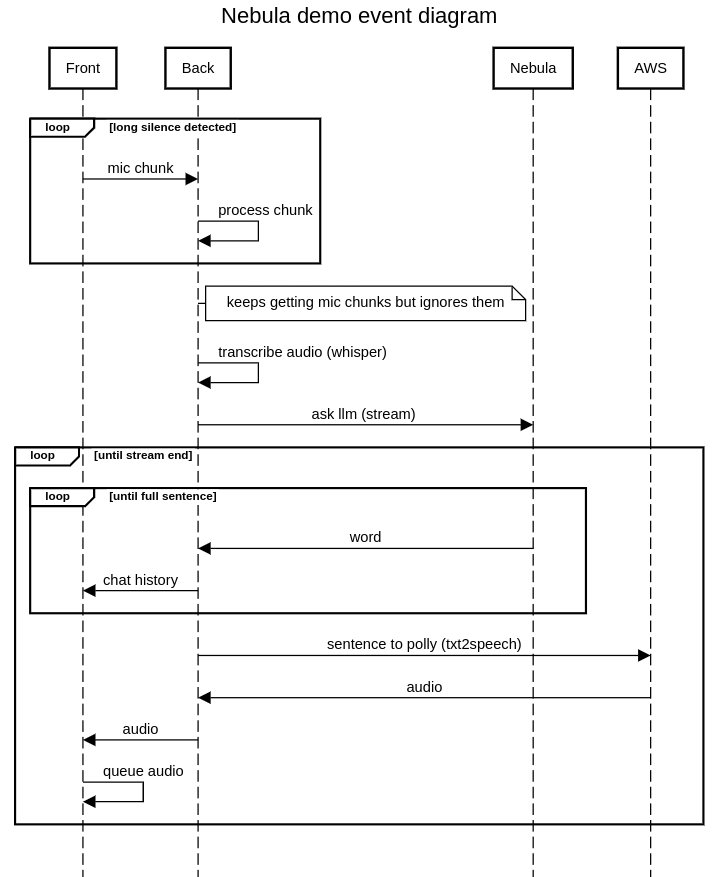
Procesa fragmentos de audio del usuario hasta que escuchamos un silencio prolongado. Esa es nuestra señal para decir «he terminado de hablar, respóndeme». Luego, los fragmentos de audio se transcriben localmente en el backend. El texto transcrito (y toda la conversación anterior) se envía a la API Nebula LLM de Symbl y la respuesta se transmite por streaming. La interfaz de usuario se actualiza a medida que cada palabra se devuelve desde la API de Nebula. Una vez que se recibe una frase completa, se envía al servicio de conversión de texto a voz de AWS Polly para obtener el audio que escuchará el usuario. Por último, el audio se reenvía al usuario, quien lo pondrá en cola y, a continuación, lo reproducirá.
El frontend y el backend se comunican a través de conectores web, lo que permite un sistema basado en eventos en el que ambas partes pueden enviar datos cuando sea necesario.
Cómo superamos las dificultades
Tiempos de medición
Claramente, si queremos asegurarnos de que tenemos una latencia baja, el primer paso consiste en medir las cosas. ¿Cuánto tiempo lleva esto? ¿Qué pasa si hacemos esto o aquello y así sucesivamente? No es necesario que sea demasiado preciso. Solo bastará con una medida experimental. Como tenemos un frontend y un backend, tenemos dos fuentes de eventos programados. Para tener una medición coherente, medimos todo lo que hay en el backend, mientras que los eventos de la interfaz se envían allí, registrando la hora de llegada. Entonces, ¿cómo estamos a la altura? Esta es una vista simplificada de los tiempos promedio de un par de ejecuciones en la versión final:
Duración media de la fase (segundos) Transcripción estándar 0.5040.211Esperando la primera palabra 1.2970.188 Esperando entre la primera palabra y la oración0.3160.234Primera generación de audio0.0730.095El primer audio llegó al usuario0.1960.064
Nuestro mayor problema parece ser esperar a que Nebula nos dé una frase completa. No podemos hacer mucho al respecto (a menos que cambiemos a un «LLM más ligero»). El tiempo total de espera para el LLM es, en promedio, de alrededor de 1,6 segundos, el tiempo más largo con diferencia. Después de esto, la transcripción ocupa un segundo lugar con diferencia. La latencia final es aceptable para que el sistema sea utilizable, pero es ligeramente superior a la indicada en la tabla. Debemos esperar a que el usuario permanezca en silencio durante un período determinado, que puede ser más largo de lo habitual en una conversación. Esto podría mejorarse, pero por ahora, hemos codificado el tiempo de espera debido al alcance limitado de la PoC.
La calidad de la transcripción es un equilibrio entre precisión y velocidad
Transcribimos el audio localmente para mayor velocidad. Symbl es mejor para las conversaciones en curso, mientras que utilizamos una versión más ligera de Open AI Whisper para transcripciones rápidas y únicas. Hay otros servicios disponibles, y las versiones más nuevas y rápidas de Whisper pueden mejorar aún más la velocidad y la calidad.
¿Lo logramos? ¿Y a dónde vamos desde aquí?
¡Sí! Desarrollamos con éxito una prueba de concepto para un robot parlante utilizando los servicios de AWS y LLM de Nebula de Symbl. Si bien el bot cumplió nuestro objetivo inicial de gestionar conversaciones sencillas, como programar llamadas, sigue siendo un trabajo en progreso. El sistema en general demuestra que dicha tecnología puede ser viable para automatizar las interacciones de voz básicas
En el futuro, planeamos centrarnos en mejorar la eficiencia y la funcionalidad del bot. Las áreas clave incluyen reducir la latencia de respuesta, mejorar la precisión de la transcripción y perfeccionar la recuperación de la información del bot para ayudar mejor a los usuarios durante las conversaciones. Explorar funciones adicionales, como las acciones de seguimiento automatizadas después de las llamadas, también será crucial para ampliar las capacidades del bot para aplicaciones del mundo real.
Síguenos en LinkedIn ¡mantente al día con lo que viene en el futuro!
Latest Insights

Building a Modern Data and AI Platform on Databricks: Architecture, Migration, and Implementation

Muttdata closes its first investment round to accelerate growth across the Americas

Building a Marketing Data Platform on Databricks: Architecture, Use Cases, and Real Results
