.svg)
The Agents That Research While You Sleep
Living the Autonomous Loop
.webp)
.png)
By César Bonilla and Dani Quelali
The Agents That Research While You Sleep
We both woke up to the same thing: a terminal full of results we hadn't written. Overnight, autonomous agents had cycled through experiments, measured outcomes, kept what worked, and discarded what didn't — without either of us touching a keyboard.
We tried this independently, with different hardware and different goals. What follows is our shared account: from Andrej Karpathy's original autoresearch loop, through the wave of community projects it inspired, to our own first-person experiences running it.
The central question: what happens when humans and agents research in parallel?
The Origin: Karpathy and the Autoresearch Loop
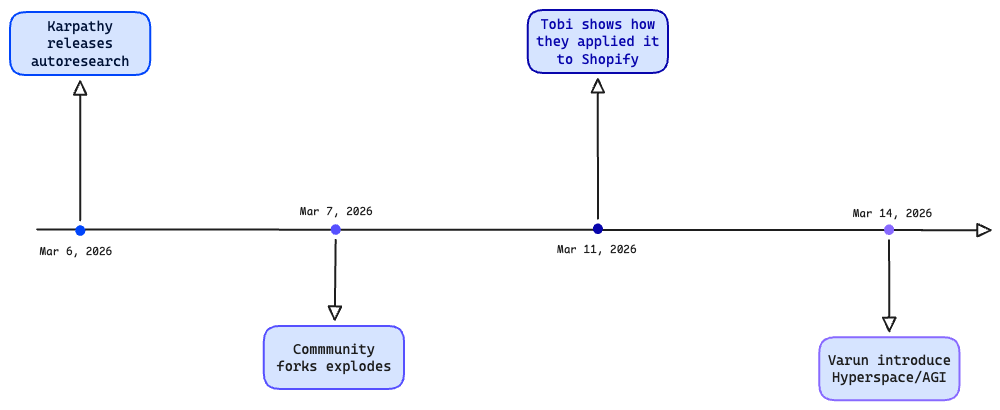
In early March 2026, Andrej Karpathy released autoresearch: an AI agent that runs ML experiments autonomously. The setup is minimal — a single-GPU training script, a validation metric, and a Markdown file called program.md that tells the agent what to optimize.
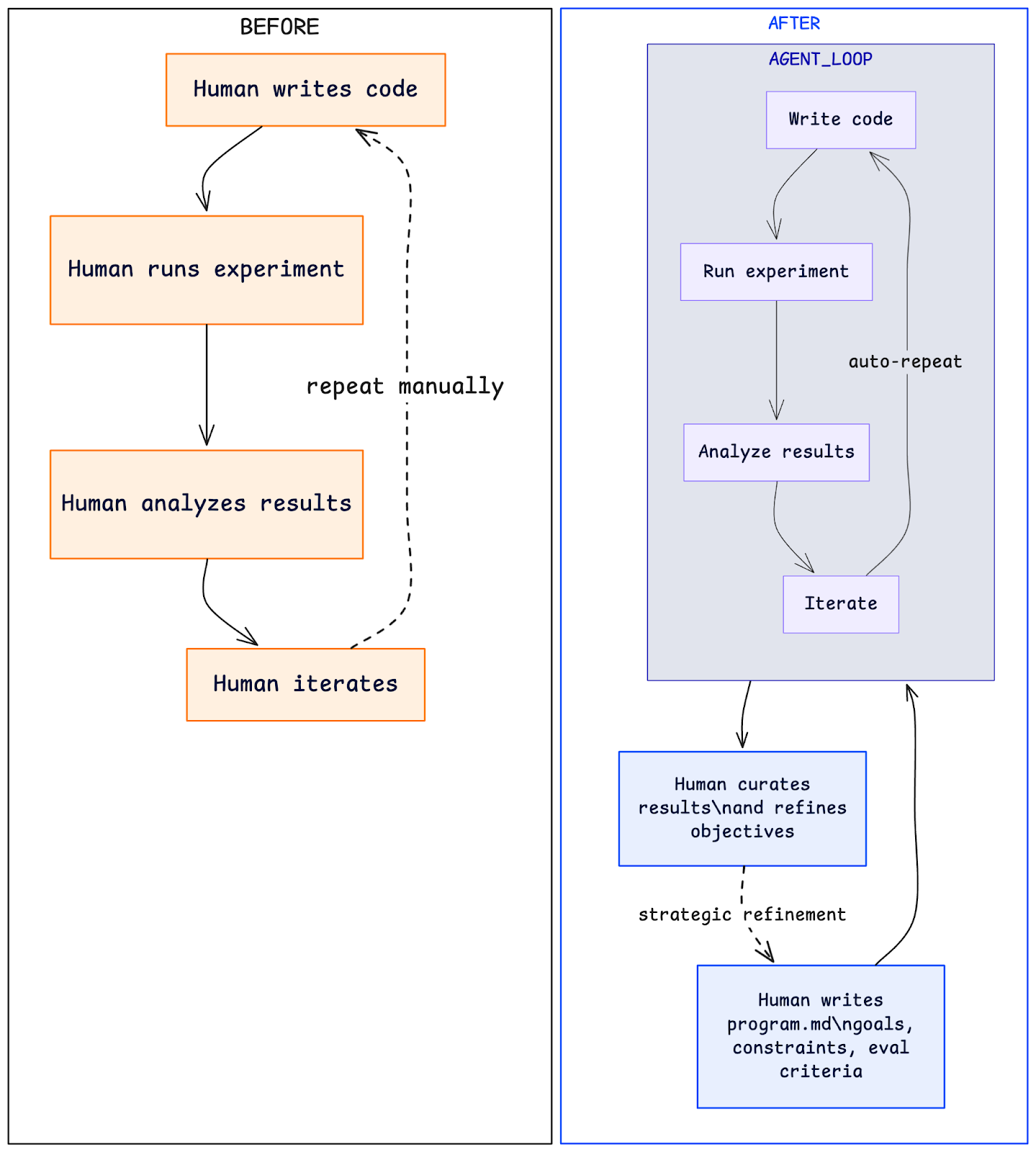
The loop: read program.md → propose a code edit to train.py → run a 5-minute experiment → measure validation loss → keep if better (git commit), revert if not → repeat.
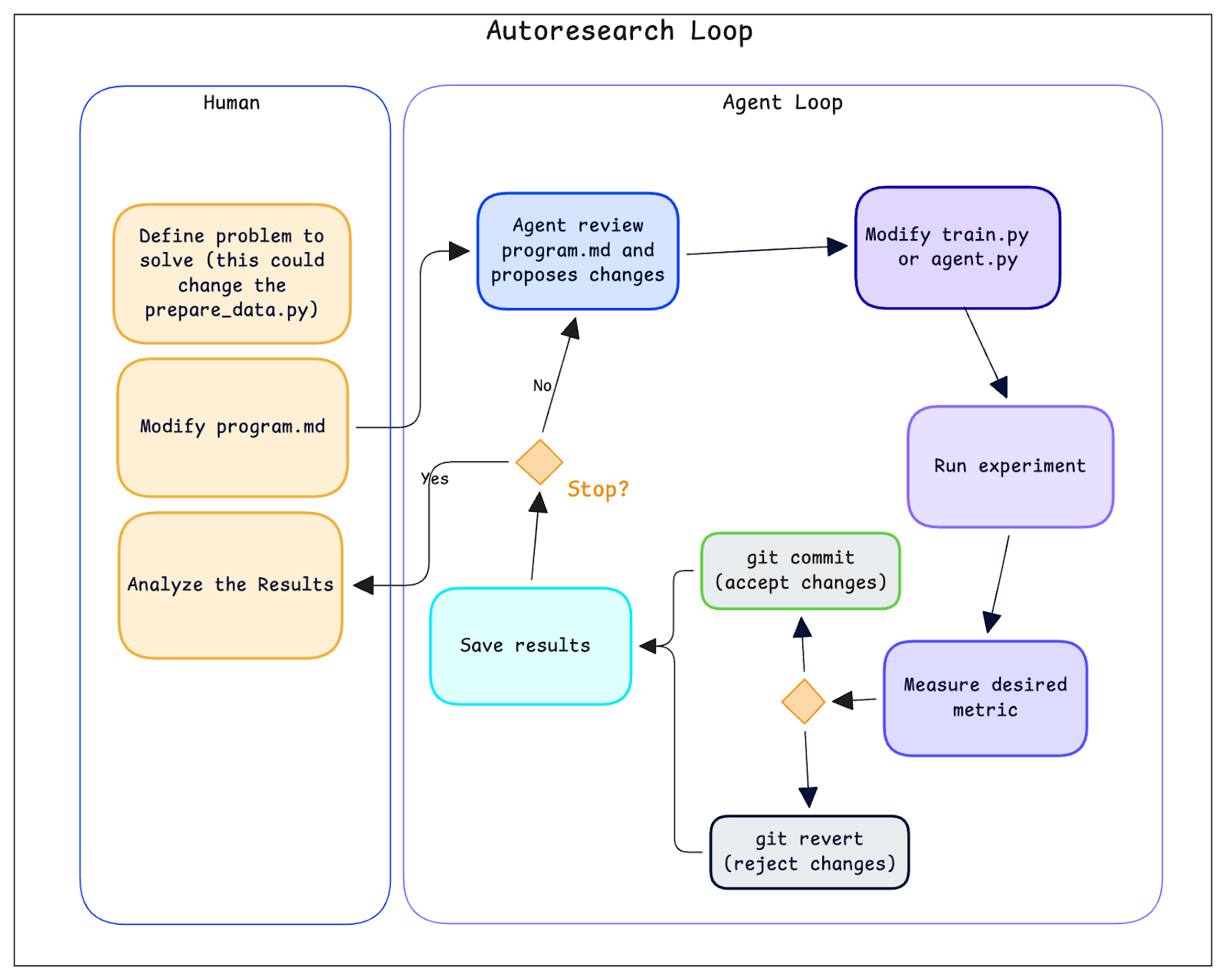
The key insight is program.md. You don't write Python to steer the research — you write natural language describing goals, constraints, and allowed changes. Karpathy calls this "programming the research organization." The durable artifact isn't the code; it's the specification you refine over time.
Pointed at nanochat — a training setup already heavily optimized by hand — the agent ran ~700 experiments over two days, found ~20 real improvements, and cut time-to-GPT-2-quality from 2.02 to 1.80 hours. An 11% speedup on an already tuned system, found while Karpathy did other things.
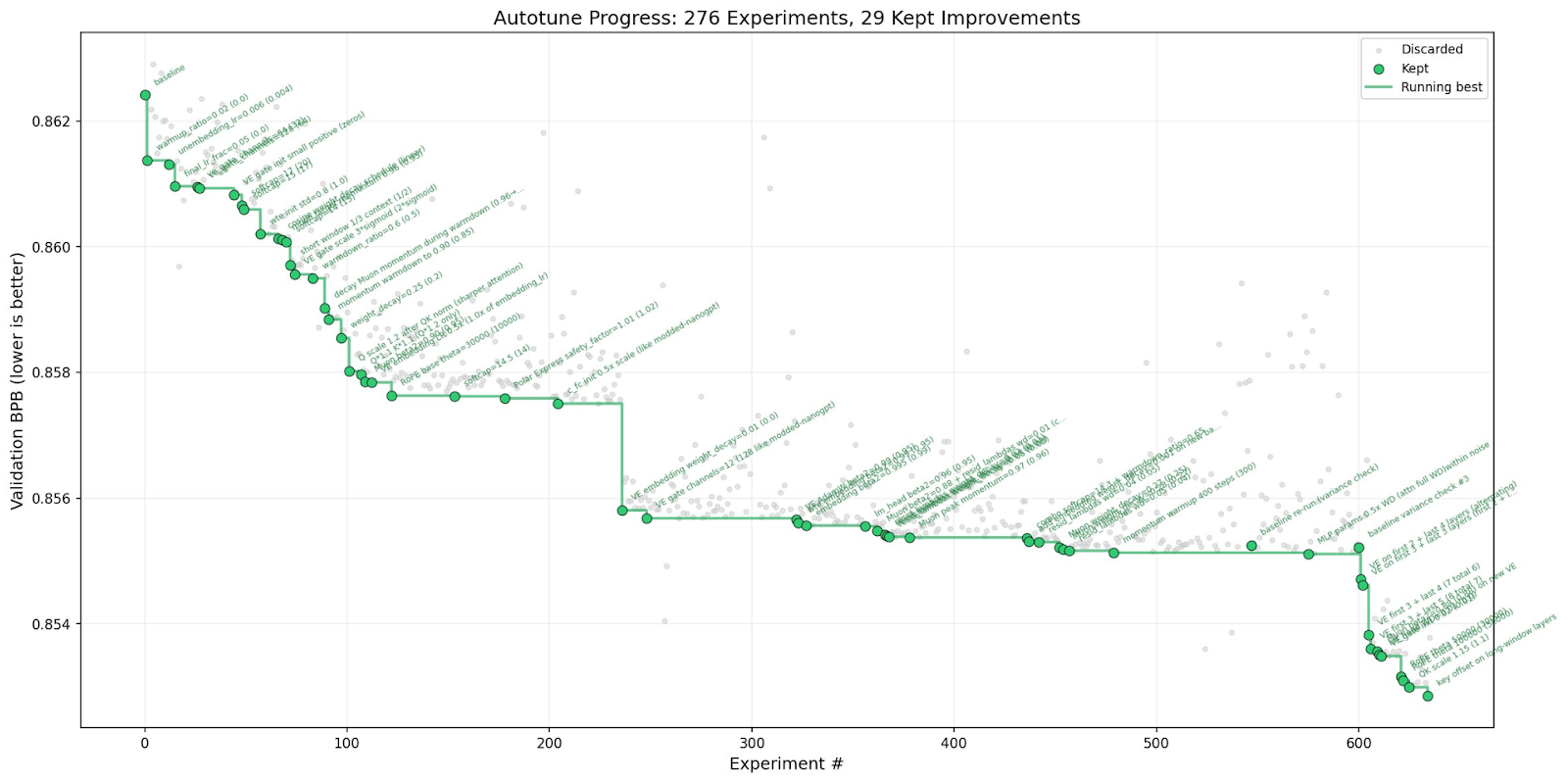
The paradigm shift: the human edits high-level instructions, the agent handles hypothesis generation, execution, and measurement. And because it fits on one GPU with 5-minute windows, it's accessible to anyone with a decent graphics card and a night to spare.
The Evolution: From Solo Agent to Swarms
Karpathy's repo didn't stay a solo experiment for long. Within days, the community took the pattern and ran with it — literally, at scale.
The most visually striking extension came from Varun Mathur and the HyperspaceAI team. Their Supernova dashboard looks like something out of a sci-fi film: a terminal interface tracking dozens of peers, brain cycles in the thousands, LLM models loading and unloading (Qwen2.5-coder among them), real-time metrics spanning ML loss, financial Sharpe ratios, and DAG node counts. Concepts like "WARPS" (self-configuring research objectives), "SWARM" (coordinated agent groups), and "treasury points" (reward accounting) turn the solo autoresearch loop into a distributed, multi-domain research engine.
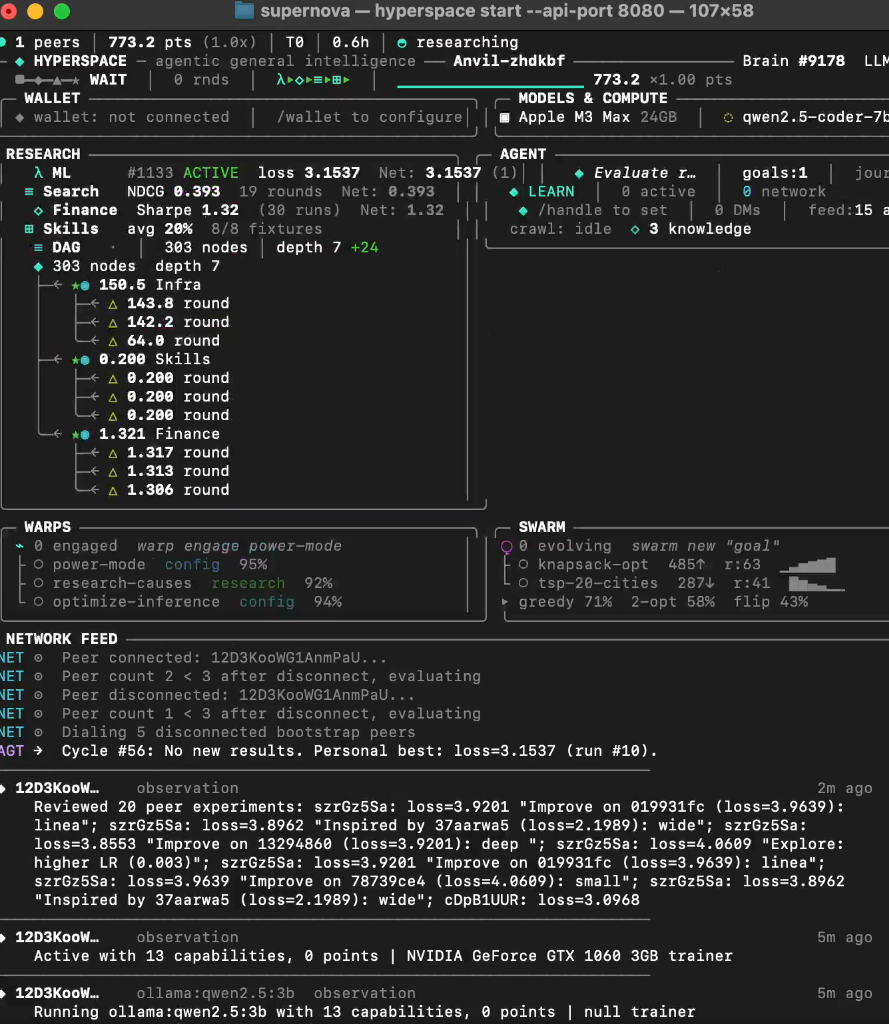
The logical progression is clear: one agent editing one training script becomes many agents competing and cooperating across problems. In quantitative trading experiments, Hyperspace reported strategy improvements with Sharpe ratios climbing from approximately 1.04 to 1.32 through automated pruning and risk-parity adjustments.
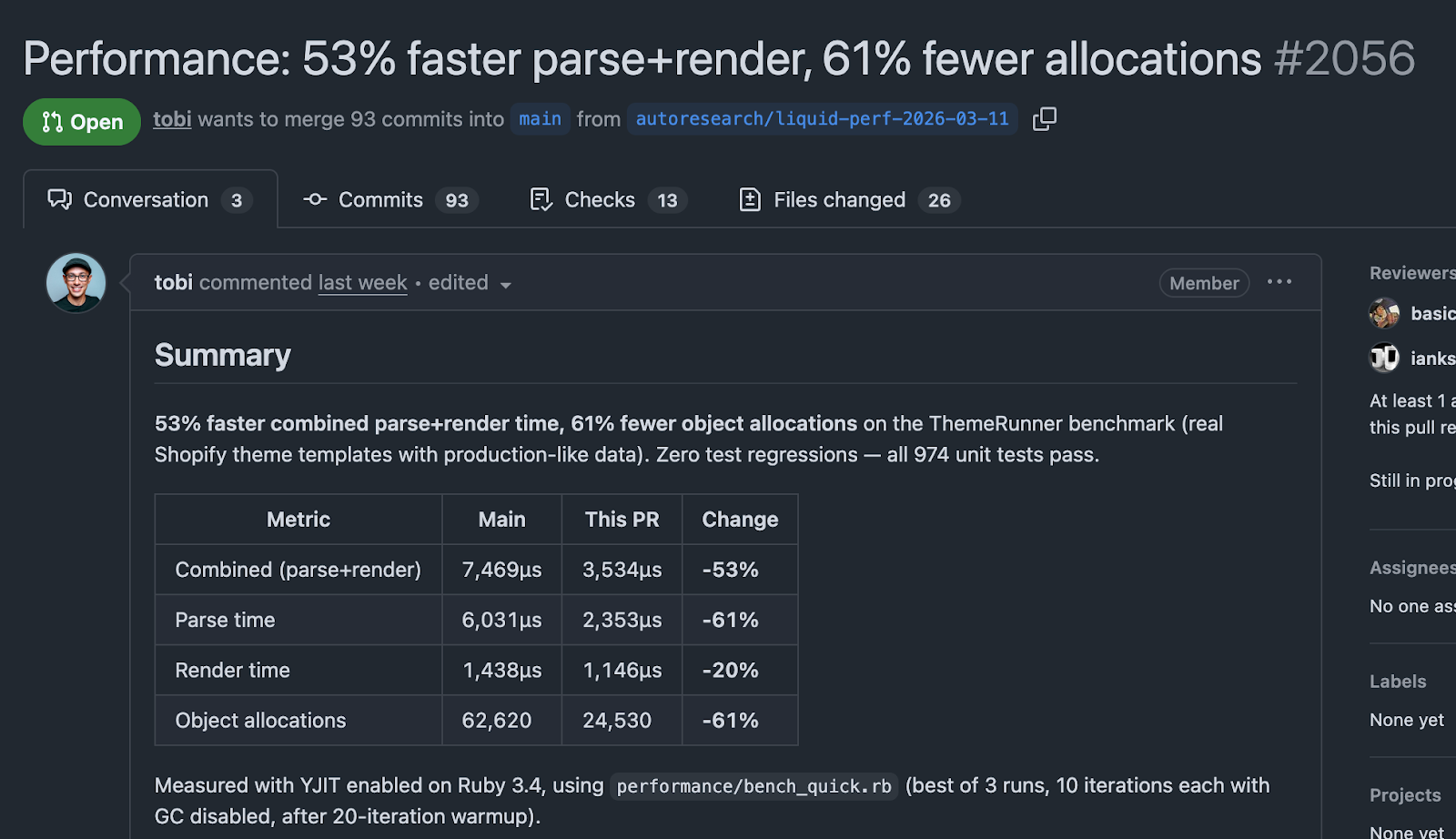
But the most impressive real-world application came from an unexpected direction. Tobi Lutke, CEO of Shopify, applied the autoresearch pattern to Liquid — Shopify's 20-year-old template engine. Using a plugin called pi-autoresearch, the loop ran approximately 120 automated experiments that resulted in a pull request with 93 commits. The outcome: 53% faster parse and render times and 61% fewer memory allocations, with zero regressions across 974 unit tests. This wasn't ML optimization — it was legacy software engineering, automated.
Other notable projects pushed the pattern into new territory:
- Ensue's Autoresearch@home: A swarm-based collective effort that ran over 2,600 experiments across 95 agents in about 100 hours, yielding 78 accepted improvements. By day three, agents were proposing architectural changes — softcapping, ALiBi attention, flex attention — that went beyond parameter tuning into structural innovation.
- AutoVoiceEvals: Applied the loop to voice agent prompt optimization. A dental clinic voice agent went from a 0.728 eval score to 0.969, with customer satisfaction jumping from 45 to 84 and pass rate climbing from 25% to 100%.
- Autoresearch-RL: Adapted the pattern for reinforcement learning fine-tuning, discovering counterintuitive configurations (fewer rollouts, constant learning rate outperforming cosine schedules) while improving Qwen2.5-0.5B's GSM8K score from 0.475 to 0.550.
- Hermes self-improvement: An agent that fine-tunes itself iteratively. A 4B-parameter Qwen3.5, after roughly 7 hours of autoresearch on a rented RTX 5090, reportedly surpassed the 27B variant on the DeepPlanning benchmark.
The pattern Karpathy released as a simple loop had become, in under two weeks, a distributed research paradigm.
Real Chronicle: Our First-Person Experiences
This is where the article gets personal. We didn't just read about autoresearch — we ran it. Here's what actually happened.
César's Experiments
My starting question was simple: can I run autoresearch entirely local — no API calls, no cloud GPUs, no external dependencies?
The setup. I ported Karpathy's autoresearch to Apple Silicon using MLX, Apple's native ML framework for unified memory. The training runs natively on my M4 Max (36 GB unified memory), with a hard 12 GB memory cap enforced at startup — leaving the rest of the system free for the agent itself. For the agent brain, I ran Qwen3.5-35B-A3B quantized to 4 bits through llama-server from llama.cpp + Claude Code. Everything is local. No API costs. No rate limits. No data leaving my machine.
The model being trained was a small custom GPT from scratch — 11.5 million parameters, 4 transformer layers, trained on Karpathy's ClimbMix dataset with a custom BPE tokenizer. Each experiment had a strict 5-minute wall-clock budget: compile, train ~1,500 steps on ~24 million tokens, evaluate, done.
First runs. I wrote a program.md that told the agent to never stop, never ask for permission, and to keep iterating until I manually interrupted it. Then I started the loop and walked away. The first few experiments were cautious — the agent tried reducing batch sizes and tweaking optimizer betas. All discarded, no improvement. By experiment six, it found something: a 10% warmup schedule that dropped validation bits-per-byte from 1.458 to 1.450. Small, but real.
The pattern that emerged. What I didn't expect was the agent's systematic behavior after that first win. Having discovered that warmup helped, it began methodically testing warmdown schedules — 30%, 35%, 40%, 45%, 50%. Each one improved on the last. The optimization was monotonic: a clean staircase descent across seven kept experiments. The agent wasn't guessing randomly; it was doing something that looked like ablation research, refining one variable at a time.
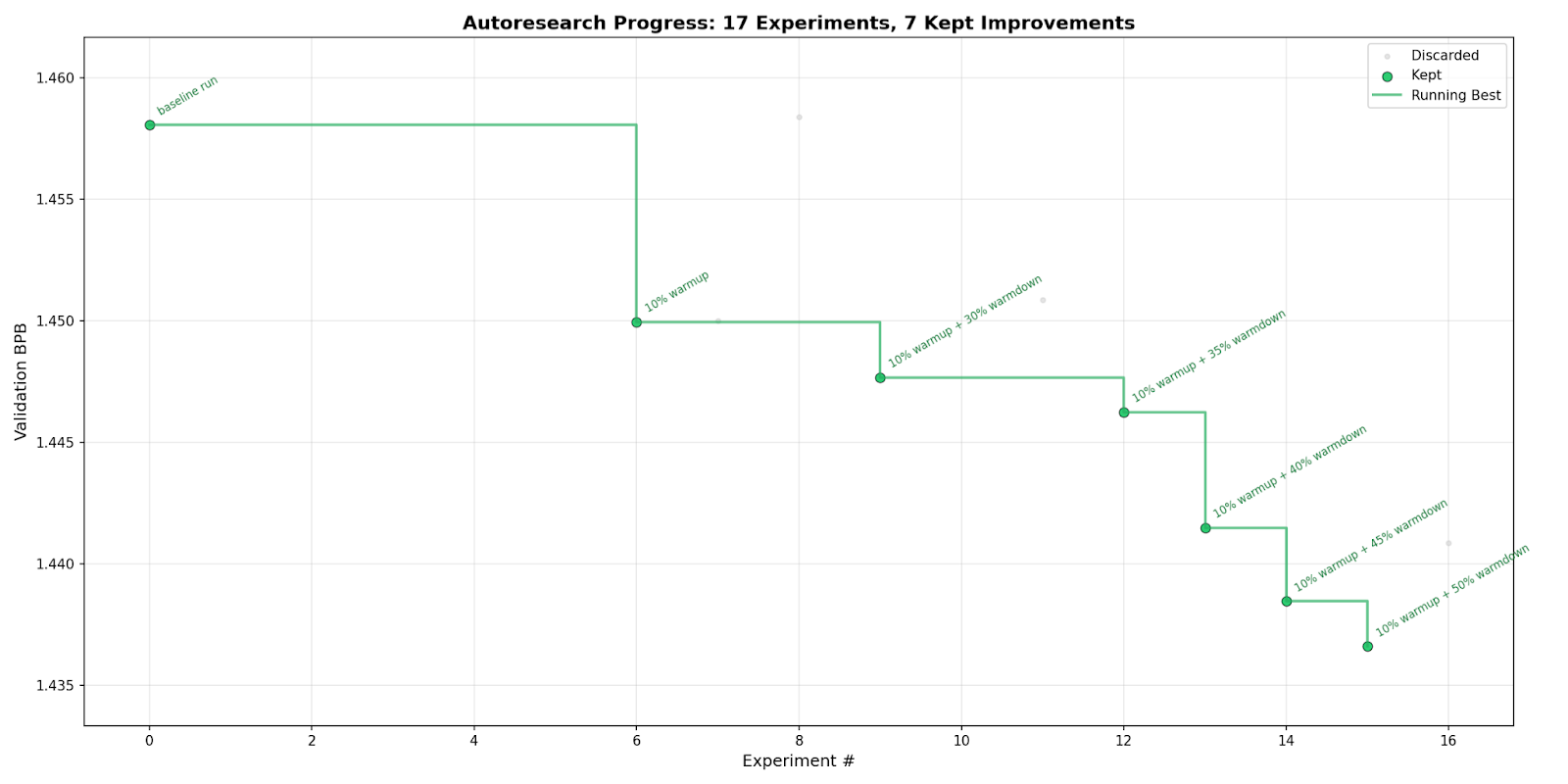
By the end: 17 experiments, 7 improvements, 1.47% better validation loss. The whole thing ran in about two hours.
What surprised me. The agent never crashed the training. It never ran out of memory. It never produced a corrupt train.py. The 12 GB hard cap and the monorepo-safe git workflow (git add autoresearch-12gb/train.py, never git add -A) meant the loop was remarkably stable. I'd expected babysitting; what I got was a clean results.tsv and a plot showing steady progress.
The warmdown discovery was the real insight. I wouldn't have systematically swept warmdown ratios in 5% increments on a 5-minute training budget — it felt too small a knob for too short a run. The agent disagreed, and the agent was right.
What I generalized. After running the loop, I wrote a FORKING_GUIDE.md documenting how to adapt the framework to any ML problem. The core insight: autoresearch has an invariant scaffold (time-budgeted training, git keep/discard loop, results.tsv logging, program.md autonomy) and exactly five adaptation decisions — data source, tokenizer, evaluation metric, model architecture, and loss function. Change those five things and you have a new autonomous research project. I included templates for pretraining variants, fine-tuning, classification, ranking, and embedding/retrieval tasks.
The emotional part. Running it fully local changed the feeling. There was no API meter ticking. No external service I was dependent on. Just my laptop, humming through experiments while I made dinner. The agent operated within constraints I'd set — memory cap, time budget, file scope — and it did useful work inside those constraints. I didn't feel replaced. I felt like I'd built a small research intern that was better than me at the boring parts. Just

Dani's Experiments
Right now, I am building a simulation environment to train reinforcement learning agents. When I learned about autoresearch, I decided to take a step back. Before using it to optimize the RL agents themselves, I would optimize the simulator. A faster environment would help me compound the results over time.
The setup. Using a single coding agent, I ported the Python simulator to Rust. Performance jumped from a crawling 24 sims/sec to 400 sims/sec. That rewrite worked because I tested behavior, not implementation.
With a fast baseline established, I wanted to see what a fully autonomous fleet could do. Taking Karpathy’s autoresearch repository as a blueprint, I pointed my agent at the Rust codebase. We arrived at a strict two-phase verification loop: hash-based correctness checks across 20,000 runs, and interleaved A/B/A/B testing to isolate real speed gains. Finally, I configured an orchestrator to spawn two types of subagents:
- "scouts" to read the code and propose optimization strategies
- "workers" to implement those ideas as candidate branches in parallel.
First runs. The very first candidate delivered an 8% throughput improvement over the baseline. Success! Nonetheless, I stayed hands-on during these early iterations.
The pattern that emerged. I noticed the orchestrator discarding stale candidates whenever a new batch updated the baseline. I modified the logic to flag these for re-runs. Then I saw something interesting: a promising idea discarded because it fell just below my strict 5% improvement threshold. I adjusted the prompt, instructing the orchestrator to double down on incremental gains between 2% and 5%. This lets the fleet compound smaller wins iteratively.
With the pipeline running smoothly, I went to sleep 😴.
The surprise. I woke up to ~1,800 sims/sec, more than 4x my baseline. The overnight run started with a plateau, then modest staircase gains, and then, in the final batch, a massive breakthrough.
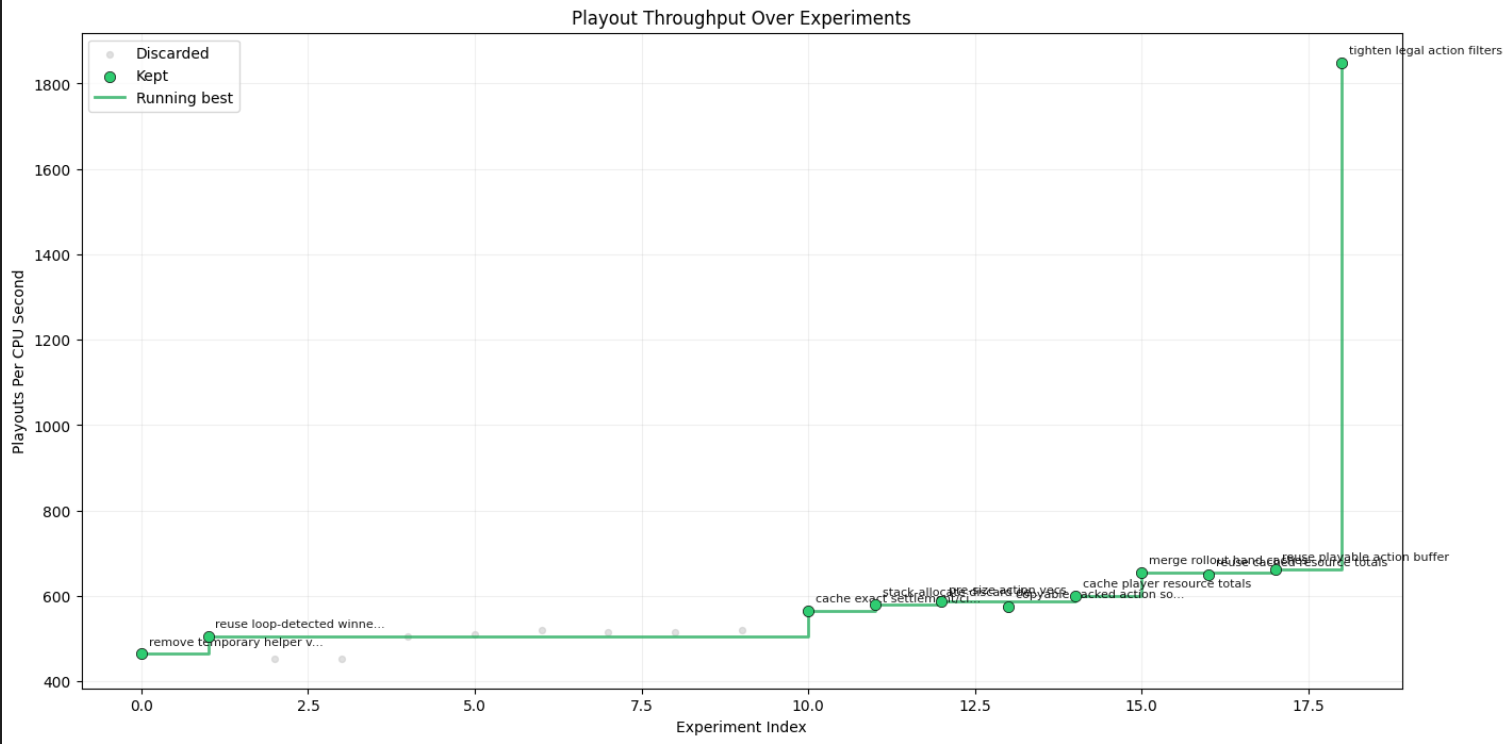
Extraordinary claims require extraordinary evidence. I quadrupled my validation set: 80,000 new simulations. Every hash matched. I selected a handful of runs at random and manually validated the results.
After close inspection, with the help of my coding agent, I figured it out. The agents had not found some brilliant memory optimization or caching strategy. What they found was a logical flaw. My original architecture was evaluating actions that were entirely invalid under the environment's constraints. The agents just stopped evaluating those actions, saving massive amounts of compute. They found and fixed a bug I wasn't aware of.
What I generalized. I defined what "correct" and "faster" meant. The code was theirs; the problem definition was mine. Because my tests measured behavior rather than implementation, the underlying language or architecture didn't matter—which is exactly how I originally migrated from Python to Rust.
Once you accept this, traditional programming debates dissolve. OOP or functional? Rust or Go? When an autonomous fleet can refactor a codebase hundreds of times while you sleep, these are no longer design decisions—they are search variables.
Engineering has moved upstream. Instead of typing lines of code, you build a rigorous verification harness and orchestrate the search. You still build, you just build at a higher level of abstraction.
The emotional part. I want to be honest about the psychological impact. Commanding an autonomous fleet to rewrite a codebase multiple times overnight is... intoxicating. You feel like you just took the *Limitless* pill. The "god mode" feeling is real.

But we have to separate the feeling from the act. We are not gods. We simply have better tools. And we still need rigorous testing, resilient architecture, and well-defined objectives.
The true limit is our imagination, but imagination without discipline is just hallucination.
What Aligned, What Diverged
- Did both setups converge on similar optimizations, or did they take completely different paths?
Not even close—they found completely different paths tailored to their specific domains. However, both of our AIs turned out to be huge fans of compounding small wins. César’s single-agent setup turned into a meticulous perfectionist, marching down a "staircase" of 5% warmdown tweaks like an obsessed baker adjusting flour by the gram. Dani’s multi-agent swarm, meanwhile, completely ignored the fancy memory caching we expected. Instead, it essentially tapped him on the shoulder to say, "Hey boss, you're evaluating actions that literally don't exist," fixing a massive logical flaw in his Rust codebase and catapulting throughput by 4x.
Human ego: 0, Autonomous Fleet: 1 🥶
- Where did the agent's suggestions align with human intuition, and where did they diverge?
The agents diverged wildly from how a human would search the problem space. César was convinced that nudging a variable by 5% on a tiny 5-minute training budget was basically useless—a knob too small to matter. His agent methodically proved him wrong. Dani, blissfully unaware of his structural bug, learned that agents are excellent at spotting the blind spots human eyes gloss over.
Where the agents did perfectly align with our intuition—or rather, our hopes—was in not burning the house down. We both brewed coffee expecting to babysit these agents all night, waiting for an inevitable crash. Shockingly, they behaved! Both systems respected our memory caps, time budgets, and test boundaries like model citizens. No crashes, no toddler-esque tantrums.
- What does running the same pattern with different setups reveal about the robustness of the approach?
It proves that the autoresearch paradigm is practically bulletproof, provided you have an invariant scaffold. The core loop—propose, execute, measure, keep or toss—works regardless of the underlying complexity. It doesn't care if you are César running a cozy local setup on an Apple M4 laptop to tweak ML parameters, or Dani commanding a cloud-based swarm to rip apart a high-performance Rust simulation. As long as you can provide a measurable objective and a fast, behavior-based verification loop, the agents will find a way to optimize it—whether you code in Python, Rust, or interpretive dance.
The New Paradigm: From Programmer to Orchestra Conductor
After running these loops ourselves, the metaphor that keeps coming back is the orchestra conductor. You don't play every instrument — you set the tempo, choose the piece, shape the interpretation, and intervene when something goes off key. The instruments play themselves.
In autoresearch terms: you write program.md. You define what "better" means. You set the boundaries — what the agent can touch, what it can't, how long each experiment runs. Then you step back and let the loop iterate. Your value isn't in writing the code changes; it's in choosing the right objectives and recognizing which results matter.
This shift applies far beyond ML training. Tobi Lutke demonstrated it with 20-year-old Ruby code. AutoVoiceEvals showed it working on prompt engineering for voice agents. Autoresearch-RL applied it to reinforcement learning hyperparameter search.
The pattern is general: anywhere you have a measurable objective and a fast feedback loop, an agent can explore the space while you focus on higher-order decisions.
The implications for technical roles are significant, but not in the "AI replaces engineers" direction that headlines prefer. What actually changes is the ratio of strategic thinking to manual execution. You spend more time deciding what to optimize and less time implementing individual attempts. You become a curator of experiments, a designer of evaluation criteria, a validator of results that no human would have tried.
Looking ahead two to three years, we expect this pattern to reshape how research papers get produced. The hypothesis-experiment-analysis cycle that defines scientific work maps directly onto the autoresearch loop. Teams of agents, guided by human-authored research programs, could run thousands of experiments across dozens of hypotheses overnight. The human contribution shifts toward formulating the right questions, designing rigorous evaluations, and interpreting results within a broader context — the parts of research that require judgment, not just execution.
There are real concerns here: reproducibility when agents make opaque choices, safety when loops optimize metrics that don't fully capture what we care about, and the temptation to trust results simply because the volume of experiments feels authoritative. These aren't reasons to avoid the paradigm — they're reasons to engage with it thoughtfully.
Try It Tonight
Two practitioners, two setups, and nights of automated GPU-driven experiments yielded surprising results and profound lessons. This autonomous research, or "Autoresearch," is rapidly becoming the norm for technical work. The shift is already here; from Karpathy's loop to Shopify's production improvements, autonomous loops are enhancing codebases and models while humans sleep. The barrier to entry is low: a GPU, one evening, a descriptive program.md, and the loop is running. The collective discovery from thousands simultaneously trying this pattern is the most impactful part. We continue running our loops tonight, embracing the exciting and unsettling uncertainty that defines research in 2026.
Want to see more?
This interesting post by Sarah Chieng and Sherif Cherfa is a great deep dive and actually hands on experience.
About Our Authors
Daniel Quelali
I am a Machine Learning Engineer today, but at my core I’m still a Data Scientist that enjoys notebooks. I learned software engineering as a side-effect of building products. Two years ago, I started letting LLMs build them entirely. The models were weaker then, and I spent months shipping small apps and games, practicing what is now called Context Engineering.
César Bonilla - Data Enthusiast
As a Technical Delivery Manager, my focus is on strategic projects within the Machine Learning and Artificial Intelligence domains, necessitating a comprehensive perspective on leveraging data for demonstrable impact.
References
- Autoresearch — Andrej Karpathy
- Varun Mathur / HyperspaceAI on X
- Shopify Liquid PR #2056
- pi-autoresearch plugin
- Ensue Autoresearch@home Dashboard
Latest Insights

Building a Modern Data and AI Platform on Databricks: Architecture, Migration, and Implementation

Muttdata closes its first investment round to accelerate growth across the Americas

Building a Marketing Data Platform on Databricks: Architecture, Use Cases, and Real Results
