.svg)
Building a Marketing Data Platform on Databricks: Architecture, Use Cases, and Real Results
Learn how to build a unified marketing data platform on Databricks — from data ingestion and governance to AI-driven optimization and real-time activation.


Building a modern marketing data platform is harder than it looks. The tools are powerful and flexible — paid media platforms, analytics layers, BI tools, experimentation frameworks — but they're each optimized for a narrow job. Over time, that specialization turns into friction. Data doesn't flow. Metrics don't agree. And your team spends more time reconciling numbers than improving them.
As Andreessen Horowitz noted in their analysis of modern data infrastructure: the rapid proliferation of data tools hasn't reduced confusion — it's increased it. Making the right architectural choices matters more now than ever.
Databricks has consistently argued that organizations struggle not because they lack tools, but because intelligence is distributed across disconnected systems.
This challenge is central to the concept of a Data Intelligence Platform Databricks' term for an environment where data, analytics, and AI are unified on a single foundation, rather than scattered across tools that each tell a different story.
Marketing is one of the clearest examples of this problem. When every platform defines its own metrics, attribution logic, and view of performance, teams spend more time reconciling reality than improving it. Optimization becomes reactive, insights arrive late, and advanced use cases fail to move from analysis to execution.
This is the context in which the shift from siloed marketing platforms to a unified Data & AI foundation becomes strategically important.
The Business Case: Why a Fragmented Marketing Data Platform Costs More Than You Think
In traditional marketing architectures, platforms gradually evolve beyond their original purpose and become implicit systems of record. Meta Ads explains performance through its own attribution model. Google Analytics focuses on behavioral journeys, often disconnected from revenue or margin. BI tools consume partial, pre-aggregated views of the business.
The consequences are tangible:
- Attribution conflicts: Google Ads claims 500 conversions, Meta claims 400, and your CRM shows 350 closed deals. Without a unified source of truth, budget allocation becomes a political negotiation rather than a data-driven decision.
- Latency in optimization: When insights require manual cross-platform analysis, optimization cycles that should take hours stretch into days or weeks. By the time a campaign is adjusted, the window of opportunity has often closed.
- Duplicated engineering effort: Every new analytics use case requires rebuilding connectors, reconciling schemas, and resolving identity across platforms—effort that compounds with each tool added to the stack.
- AI readiness gap: Advanced use cases like predictive lifetime value, multi-touch attribution modeling, or real-time bid optimization require feature-rich, clean, unified datasets. Siloed architectures make assembling these datasets a project in itself.
Databricks has described this broader pattern when contrasting fragmented analytics stacks with the Lakehouse approach. Each platform optimizes locally, but no system optimizes globally. Cross-channel analysis becomes manual, attribution debates dominate conversations, and optimization logic is constrained by platform boundaries.
The stack remains functional for reporting, but fragile when used as decision infrastructure.
Separating Execution from Intelligence
A recurring theme in modern data architecture is the separation between systems of execution and systems of intelligence. Marketing platforms execute: they deliver ads, collect interactions, and apply bids. Intelligence—where performance is evaluated, models are trained, and decisions are validated—must live outside those platforms, on infrastructure designed for analytical depth and cross-domain reasoning.
This separation is core to the Data Intelligence Platform. Built on the Lakehouse architecture, Databricks unifies data engineering, analytics, machine learning, and governance in a single environment. Marketing data is treated the same way as product, finance, or customer data: as input to shared decision systems rather than isolated reports.
This architectural distinction is what differentiates a true intelligence layer from a collection of loosely connected tools. When your marketing data shares the same catalog, governance model, and compute layer as your product telemetry and financial data, entirely new classes of analysis become possible—such as correlating ad spend with actual product engagement cohorts, or feeding CRM-validated conversions back into bid optimization models.
Marketing Data Platform Architecture on Databricks: Lakeflow, Delta Lake, Unity Catalog, MLflow, Genie & Lakebase for a Unified Marketing Data & AI Platform
The following reference architecture illustrates how marketing data flows from source systems through a governed Lakehouse into AI-driven optimization and activation. This is not a theoretical exercise—each component maps to production-ready Databricks capabilities.
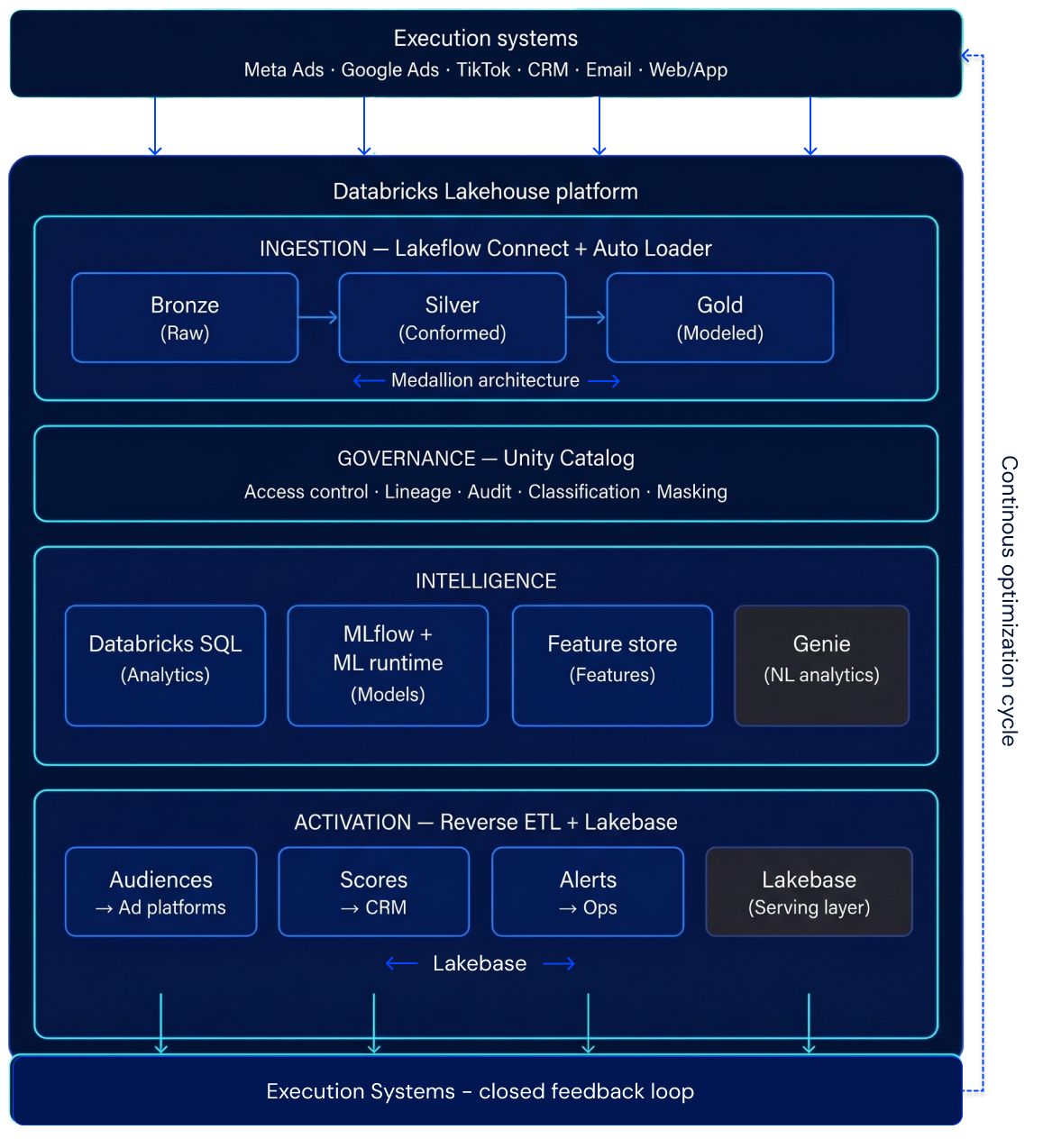
Layer 1: Ingestion — Lakeflow Connect + Medallion Architecture
Fragmentation at ingestion propagates downstream. If marketing data enters the system inconsistently, every analytical and AI workflow inherits that complexity. Instead of treating paid media data as an external input that requires bespoke pipelines, campaign structures, and performance signals are ingested directly into the lakehouse as governed, analytics-ready data.
Source connectors via Lakeflow Connect:
- Meta Ads (native connector): Campaign structures, ad set configurations, spend metrics, and performance signals ingested directly into Delta tables—no bespoke pipelines required. Data lands with consistent schemas, automatic refresh, and full lineage tracking.
- Google Analytics 4 (GA4): Event-level behavioral data exported to BigQuery, then ingested into Databricks via the GA4 Raw Data connector. Session, event, and user-property data arrives with consistent semantics.
- Google Ads, TikTok Ads, LinkedIn Ads: Connected through Lakeflow partner connectors or Fivetran/Airbyte integrations landing directly into the Lakehouse.
- CRM & transactional data: Salesforce, HubSpot, or internal databases connected via JDBC/Lakeflow to provide the revenue side of the attribution equation.
Medallion architecture for marketing data:
Data flows through Bronze → Silver → Gold layers, each adding refinement:
- Bronze (Raw): Raw API responses from ad platforms, raw GA4 event exports, CRM extracts. Stored as-is in Delta format for auditability and replay. Schema evolution handled automatically by Auto Loader.
- Silver (Cleaned & Conformed): Standardized naming conventions across platforms (e.g., campaign_id, spend_usd, impressions, clicks, conversions). Identity resolution applied—matching user identifiers across GA4 user_pseudo_id, Meta fbclid, and CRM contact_id into a unified customer_id. Timestamps normalized to UTC. Currency conversions applied.
- Gold (Business-Ready): Aggregated, modeled datasets purpose-built for consumption. Examples include a cross-channel attribution table, a customer lifetime value feature store, a campaign performance cube with blended ROAS metrics, and audience segment definitions.
Layer 2: Governance — Unity Catalog
Unification without governance does not scale. Marketing datasets often include identity signals, audience definitions, and conversion data that carry regulatory and business risk.
Unity Catalog provides the governance backbone:
- Centralized access control: Fine-grained permissions at the catalog, schema, table, and column level. PII columns like email or phone can be masked or restricted to specific teams while keeping the rest of the dataset accessible.
- Data lineage: Automatic, column-level lineage tracking from Bronze through Gold. When a ROAS metric looks wrong, you can trace it back through every transformation to the raw API response.
- Audit logging: Every query, every access, every modification is logged. Essential for GDPR/CCPA compliance when marketing data contains personal identifiers.
- Data classification: Tags and labels for sensitive data (PII, financial, audience segments) enforced consistently across notebooks, SQL queries, dashboards, and ML training jobs.
Layer 3: Analytics & AI — From Dashboards to Predictive Models
With unified, governed data in place, teams can move from reactive reporting to proactive optimization. This is where the Lakehouse delivers the most value—not just in efficiency, but in decision quality. In siloed environments, analytics is limited by each platform’s scope, forcing manual consolidation and making it difficult to answer cross-channel business questions.
On Databricks, these questions become straightforward SQL queries on governed Gold tables. Databricks SQL enables unified analytics across sources, with native BI integrations, allowing teams to build dashboards that combine marketing, CRM, and product data without relying on new pipelines.
Capabilities like query federation, materialized views, and alerts ensure fast, consistent metrics and enable early detection of performance shifts.
This marks the shift from reporting on what happened to understanding what is happening and acting on it.
MLflow for marketing models:
The same platform that houses your analytics also trains and serves your models. No data movement, no separate ML infrastructure.
- Multi-touch attribution: Data-driven attribution models (Shapley value, Markov chains) trained on unified touchpoint data spanning all channels. Registered and versioned in MLflow.
- Customer Lifetime Value prediction: Feature engineering from behavioral (GA4), transactional (CRM), and engagement (email/push) data—all available in one catalog. Models trained in Databricks, tracked in MLflow, served via Model Serving.
- Budget optimization: Constrained optimization models that recommend spend allocation across channels based on predicted marginal ROAS, using historical cross-channel data that no single platform could provide.
Databricks Genie for Natural-Language Analytics
Genie is an AI-powered interface in Databricks that allows business users to query data in plain English and get accurate answers directly from governed Gold tables—no SQL required.
Because it operates on top of Unity Catalog and leverages a consistent semantic layer, Genie understands schemas, metrics, and business definitions, ensuring results are consistent, secure, and aligned with the single source of truth. This eliminates dependency on data teams, reduces delays, and avoids inconsistencies from manual reporting.
For marketing teams, this significantly shortens the path from question to insight, enabling faster, data-driven decisions. Combined with dashboards and alerts, Genie completes the analytics layer by supporting structured monitoring, real-time detection, and on-demand exploration—all on the same governed data foundation.
Layer 4: Activation — Closing the Loop with Reverse ETL
Insights only create value when they are operationalized. Databricks blogs on operational analytics consistently reinforce this idea. Within a unified Data & AI foundation, reverse ETL acts as the activation layer that closes the loop — and with the introduction of Lakebase, Databricks now offers a built-in operational database that makes this activation even more seamless.
Optimization outputs — budget recommendations, audience segments, prioritization scores, suppression lists — are written back to execution systems from the same governed environment in which they were produced. Traditionally this requires reverse ETL pipelines to push data outward; Lakebase introduces an alternative: a fully managed, transactional database natively integrated into the Lakehouse that can serve these outputs directly to operational applications with low-latency reads, eliminating the need to replicate data into external systems for many use cases.
Practical activation patterns:
- High-value audience segments → pushed to Meta Custom Audiences and Google Ads Customer Match via reverse ETL, enabling lookalike targeting based on ML-predicted LTV rather than platform-native heuristics. Alternatively, applications consuming segments via API can query Lakebase directly, reducing pipeline complexity and sync lag.
- Churn risk scores → written to the CRM to trigger retention campaigns before customers lapse, or served from Lakebase to internal retention tools that need real-time access to the latest scores without waiting for batch ETL cycles.
- Budget reallocation recommendations → surfaced in Databricks SQL dashboards for marketing ops, with automated alerts when predicted ROAS drops below threshold. Lakebase can also back custom operational UIs that allow marketing teams to review and approve reallocations before they take effect.
- Suppression lists → recently converted customers excluded from acquisition campaigns in real time, reducing wasted spend. Lakebase is particularly well suited here: its transactional consistency ensures that suppression decisions reflect the most current conversion data, avoiding the staleness that batch reverse ETL can introduce.
The choice between reverse ETL and Lakebase is not binary — they complement each other. Reverse ETL remains the right pattern when the consuming system is a third-party platform (ad networks, CRMs, ESPs) that requires data to be pushed into its own storage. Lakebase shines when the consuming application can query an API or database directly, since it eliminates an entire class of synchronization pipelines while keeping data under Unity Catalog governance. In both cases, because analytics, machine learning, and activation operate on shared data models, the resulting pipelines are simpler, auditable, and resilient.
This enables a continuous feedback loop where execution generates signals, intelligence produces decisions, and outcomes inform the next optimization cycle — with Lakebase ensuring that the operational layer is as tightly integrated with the Lakehouse as the analytical one.
Final Takeaway
Databricks positions the Lakehouse and the Data Intelligence Platform as an answer to fragmented analytics. In marketing, this framing is especially relevant—because marketing is where fragmentation is most acute and where the cost of disconnected intelligence is measured directly in wasted spend and missed revenue.
When marketing data, analytics, and AI live on a unified platform, performance evaluation becomes continuous, cross-channel, and outcome-driven. Optimization logic operates across platforms rather than inside them. And the gap between "insight" and "action" shrinks from days to minutes.
By unifying ingestion, governance, analytics, optimization, and activation on Databricks, organizations move beyond tool-centric reporting toward system-level marketing intelligence. Competitive advantage no longer comes from adding more platforms, but from how effectively data and AI are unified behind them.
That's the difference between a collection of marketing tools and a true marketing data platform — one built to optimize across channels, not just within them.
If you're evaluating whether Databricks is the right foundation for your marketing data platform, we're happy to share what we've learned building these systems across industries. Mutt Data was named LATAM AI Partner of the Year by Databricks — let's talk.
Do you need to build your marketing data platform on Databricks? Do you need Databricks experts or teams of experts? Let's meet!
www.muttdata.ai / email: sales@muttdata.ai
Latest Insights
.png)
Databricks Ventures Invests in Muttdata to Accelerate Enterprise AI Across the Americas


Building a Modern Data and AI Platform on Databricks: Architecture, Migration, and Implementation
